pacman::p_load(
tidyverse, # ggplot, mutate(), cleaning...
tsibble, # as_tsibble()
fable, # model(...), forecast(), tidy(), glance()...
feasts, # ACF(), PACF()
ggtime, # autoplot() for tsibbles
patchwork, # + and / for ggplots
rio # import()
)Autoregressive (AR) Models
Chapter 4: Lesson 3
Learning Outcomes
Characterize the properties of an \(AR(p)\) stochastic process
- Define an \(AR(p)\) stochastic process
- Express an \(AR(p)\) process using the backward shift operator
- State an \(AR(p)\) forecast (or prediction) function
- Identify stationarity of an \(AR(p)\) process using the backward shift operator
- Determine the stationarity of an \(AR(p)\) process using a characteristic equation
Check model adequacy using diagnostic plots like correlograms of residuals
- Characterize a random walk’s second order characteristics using a correlogram
- Define partial autocorrelations
- Explain how to use a partial correlogram to decide what model would be suitable to estimate an \(AR(p)\) process
- Demonstrate the use of partial correlogram via simulation
Preparation
- Read Section 4.5
Learning Journal Exchange (10 min)
Review another student’s journal
What would you add to your learning journal after reading another student’s?
What would you recommend the other student add to their learning journal?
Sign the Learning Journal review sheet for your peer
Packages
Class Activity: Definition of Autoregressive (AR) Models (10 min)
We now define an autoregressive (or AR) model.
In short, this means that the next observation of a time series depends linearly on the previous \(p\) terms and a random white noise component.
We have seen some special cases of this model already.
We now explore the autoregressive properties of this model.
Class Activity: Exploring \(AR(1)\) Models (10 min)
Definition
Recall that an \(AR(p)\) model is of the form \[ x_t = \alpha_1 x_{t-1} + \alpha_2 x_{t-2} + \alpha_3 x_{t-3} + \cdots + \alpha_{p-1} x_{t-(p-1)} + \alpha_p x_{t-p} + w_t \] So, an \(AR(1)\) model is expressed as \[ x_t = \alpha x_{t-1} + w_t \] where \(\{w_t\}\) is a white noise series with mean zero and variance \(\sigma^2\).
Second-Order Properties of an \(AR(1)\) Model
We now explore the second-order properties of this model.
Correlogram of an \(AR(1)\) process
Small Group Activity: Simulation of an \(AR(1)\) Process
Class Activity: Partial Autocorrelation (10 min)
Definition of Partial Autocorrelation
For example, the partial correlation for lag 4 is the correlation not explained by lags 1, 2, or 3.
On page 81, the textbook states that in general, the partial autocorrelation at lag \(k\) is the \(k^{th}\) coefficient of a fitted \(AR(k)\) model. This implies that if the underlying process is \(AR(p)\), then all the coefficients \(\alpha_k=0\) if \(k>p\). So, an \(AR(p)\) process will yield partial correlations that are zero after lag \(p\). So, a correlogram of partial autocorrelations can be helpful to determine the order of an appropriate \(AR\) process to model a time series.
Example: McDonald’s Stock Price
Here is a partial autocorrelation plot for the McDonald’s stock price data:
Show the code
# Set symbol and date range
symbol <- "MCD"
company <- "McDonald's"
# Retrieve static file
stock_df <- rio::import("https://byuistats.github.io/timeseries/data/stock_price_mcd.parquet")
# Transform data into tibble
stock_ts <- stock_df %>%
mutate(
dates = date,
value = adjusted
) %>%
select(dates, value) %>%
as_tibble() %>%
arrange(dates) |>
mutate(diff = value - lag(value)) |>
as_tsibble(index = dates, key = NULL)
pacf(stock_ts$value, plot=TRUE, lag.max = 25)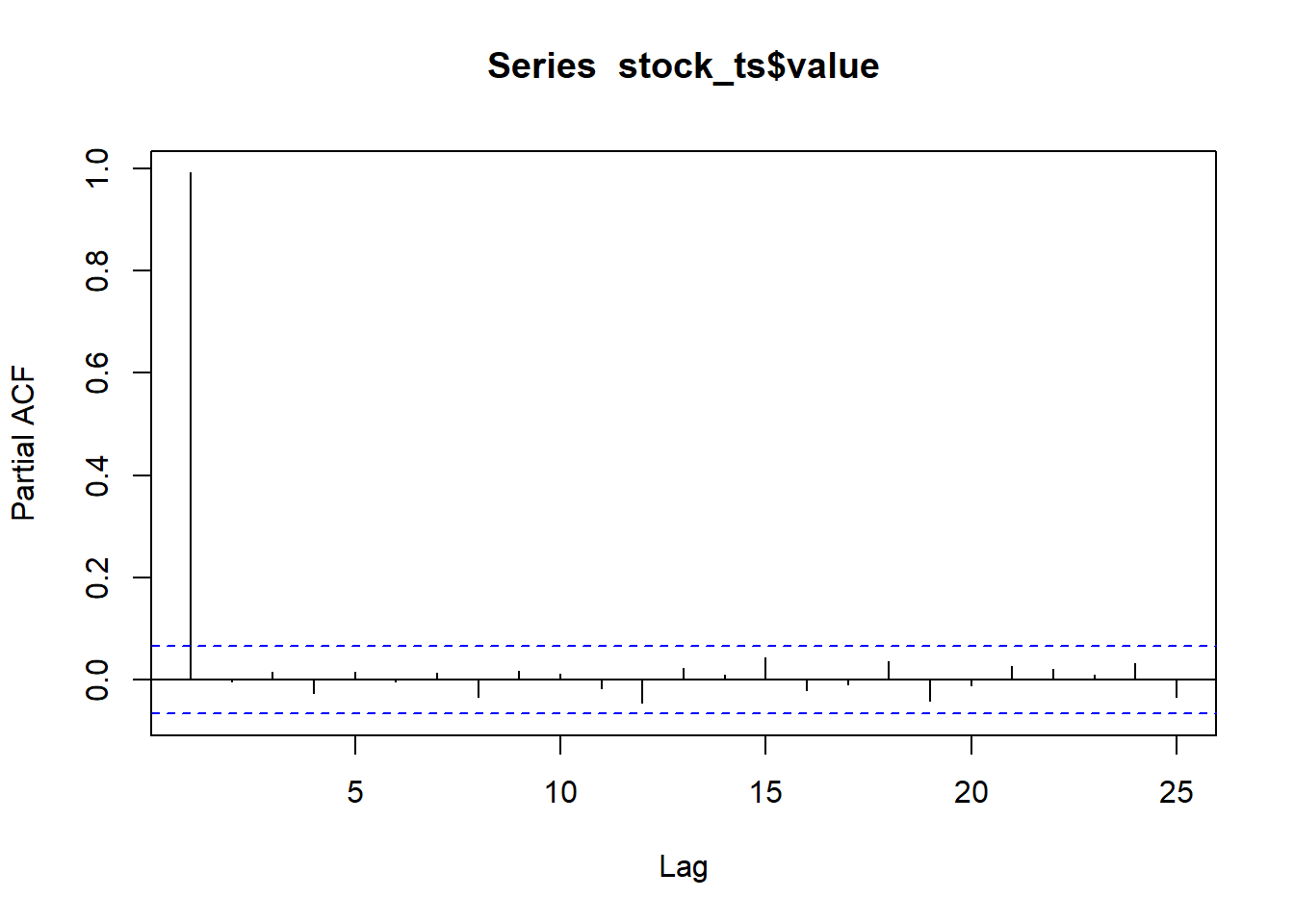
The only significant partial correlation is at lag \(k=1\). This suggests that an \(AR(1)\) process could be used to model the McDonald’s stock prices.
Partial Autocorrelation Plots of Various \(AR(p)\) Processes
Here are some time plots, correlograms, and partial correlograms for \(AR(p)\) processes with various values of \(p\).
Shiny App
Class Activity: Stationary and Non-Stationary AR Processes (15 min)
The roots of the characteristic polynomial are the values of \(\mathbf{B}\) that make the polynomial equal to zero–i.e., the values of \(\mathbf{B}\) that make \(\theta_p(\mathbf{B}) = 0\). These are also called the solutions of the characteristic equation. The roots of the characteristic polynomial can be real or complex numbers.
We now explore an important result for AR processes that uses the absolute value of complex numbers.
First, we will find the roots of the characteristic polynomial (i.e. the solutions of the characteristic equation) and then we will determine if the absolute value of these solutions is greater than 1.
We can use the polyroot function to find the roots of polynomials in R. For example, to find the roots of the polynomial \(x^2-x-6\), we apply the command
polyroot(c(-6,-1,1))[1] 3-3.308722e-23i -2+3.308722e-23iNote the order of the coefficients. They are given in increasing order of the power of \(x\).
Of course, we could simply factor the polynomial: \[ x^2-x-6 = (x-3)(x+2) \overset{set}{=} 0 \] which implies that \[ x = 3 ~~~ \text{or} ~~~ x = -2 \]
Practice computing the absolute value of a complex number. \(\ \)
We will now practice assessing whether an AR process is stationary using the characteristic equation.
Homework Preview (5 min)
- Review upcoming homework assignment
- Clarify questions