Comparing Categorical Data with Multiple Categories
When working through statistical inference for means, we progressed from learning 1-sample t-tests to 2-sample t-tests. When we wanted to compare a quantitative variable between multiple groups, we introduced ANOVA. The hypothesis test changed and we introduced the F-statistic.
Recall that the F-statistics was based on a ratio of squared quantities and was therefore always positive and skewed right.
Similarly, when we want to compare a categorical variable across multiple groups, we must modify the hypothesis test from the 2-sample proportion test and introduce a new test statistic: . The Greek letter, , is pronounced like “ki” in “kite”, not like “chi” in “tai chi”.
As can be seen from its name, is a squared value and is thus always positive and right skewed like the F-statistic.
Degrees of Freedom
The distribution also has degrees of freedom that determine its shape.
Where is the number of rows and is the number of columns in a summary table.
Hypothesis Test
The null and alternative hypotheses test for test for independence are always the same.
While not a fan of the double negative, it serves a technical purpose. Mathematically, we get the same test statistic and p-value if we swap rows and columns. We cannot say the row variable depends on the column variable without also saying that the column variable depends on the row variable.
Think of Alice at the Mad Hatter’s tea party:
“Then you should say what you mean,” the March Hare went on. “I do,” Alice hastily replied; “at least-at least I mean what I say-that’s the same thing, you know.”
“Not the same thing a bit!” said the Hatter. “Why, you might just as well say that ‘I see what I eat’ is the same thing as ‘I eat what I see’!”
“You might just as well say,” added the March Hare, “that ‘I like what I get’ is the same thing as ‘I get what I like’!”
“You might just as well say,” added the Dormouse, which seemed to be talking in its sleep, “that ‘I breathe when I sleep’ is the same thing as ‘I sleep when I breathe’!”
“It is the same thing with you.” said the Hatter,”
So we are resigned to conclude that we have sufficient/insufficient evidence that they are not independent.
Tests for Independence in R
The R code for tests for independence is simple, especially when we have raw data. We can easily create a table using the table_name <- table(col1, col2) function, then insert table_name into the chisq.test(table_name) function.
location motivation
1 Europe Wellness
2 Europe Wellness
3 Europe Wellness
4 Europe Wellness
5 Europe Wellness
6 Europe Wellness
7 Europe Wellness
8 Europe Wellness
9 Europe Wellness
10 Europe Wellness
11 Europe Wellness
12 Europe Wellness
13 Europe Wellness
14 Europe Wellness
15 Europe Wellness
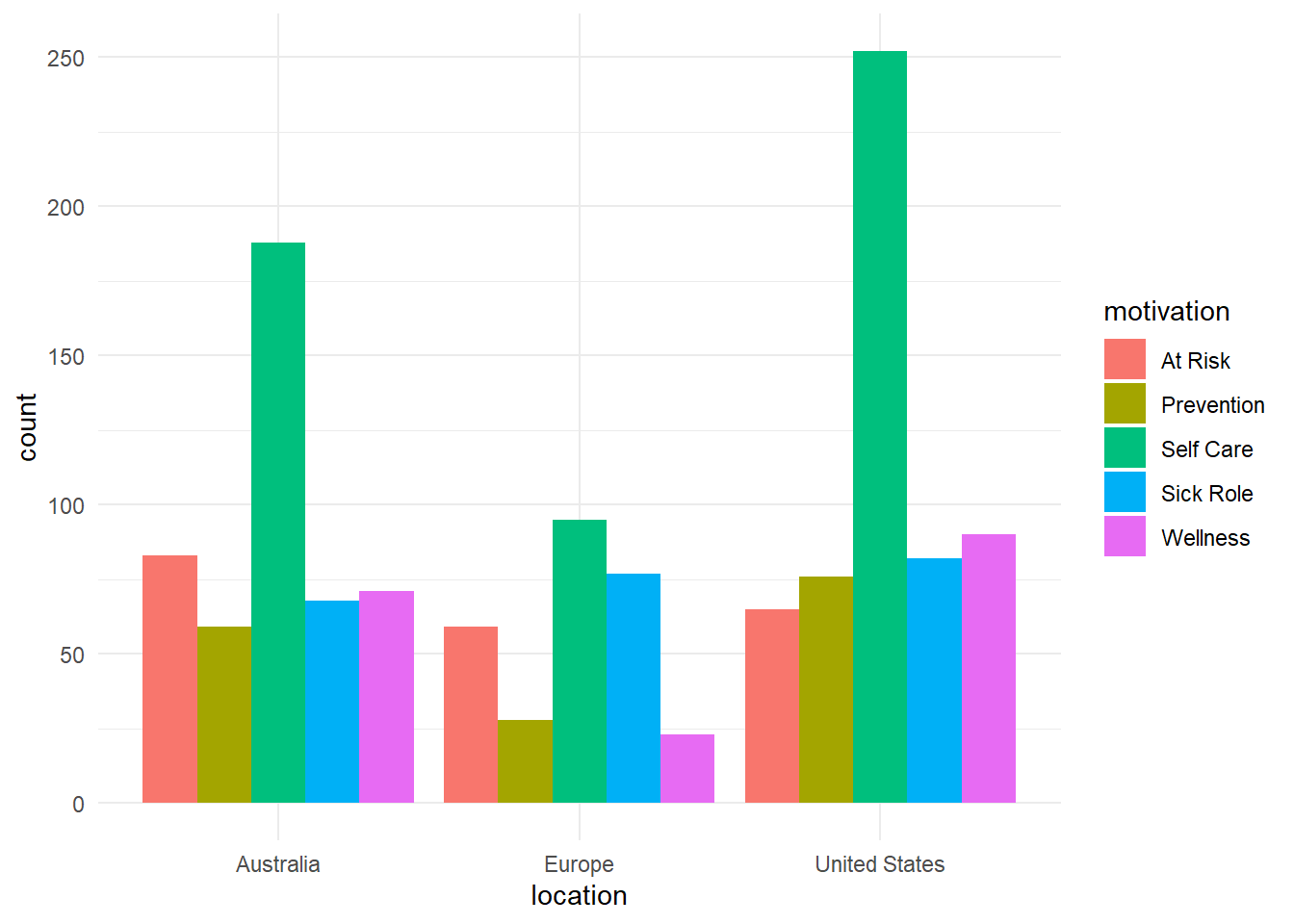
In this dataset, we have a column with “location” indicating the region of the respondents, and the motivation for visiting a chiropractor. Our null and alternative hypotheses are:
We have sufficient evidence to conclude that why you go to the chiropractor is not independent of where you live.
Test Requirements
Recall that 2-sample tests for proportions needed an at least 10 expected successes and at least 10 expected failures ( and ) for the test statistic to be valid.
For a test we need to check the expected counts for all the different combinations.
We don’t need to fret about the math behind the expected count calculation. Intuitively, if there was no relationship between the two variables you would expect all the row totals to be proportionally distributed across the column groups.
We only need to check that all expected counts are greater than 5.
chisq.test(chiro_table)$expected >=5
At Risk Prevention Self Care Sick Role Wellness
Australia TRUE TRUE TRUE TRUE TRUE
Europe TRUE TRUE TRUE TRUE TRUE
United States TRUE TRUE TRUE TRUE TRUE
Visualization
We can use ggplot() to create nice bar charts to help interpret the results.
ggplot(chiropractic, aes(x = location, fill = motivation)) +geom_bar(position ="dodge") +theme_minimal()
Summarized Data
Sometimes we only get a summarized table instead of raw data in columns. When this happens, we have to type in the data into a format in R that the chisq.test() function can recognize.
Suppose we have a summary table:
knitr::kable(chiro_table)
At Risk
Prevention
Self Care
Sick Role
Wellness
Australia
83
59
188
68
71
Europe
59
28
95
77
23
United States
65
76
252
82
90
We can type in the data into a matrix format as follows:
Be sure to EXCLUDE row and column totals if they are included in the summary table.
Your Turn
A public opinion poll surveyed a simple random sample of 1000 voters. Respondents were classified by gender (female or male) and by voting preference (Republican, Democrat, or Independent). The results are presented here:
Do men’s voting preferences differ significantly from women’s voting preferences?
Use a level of significance of
State the null and alternative hypothesis:
What are the degrees of freedom for this hypothesis test?
Perform a hypothesis test:
# Fill in the table information by row, separating the values with a commatable_data <-matrix(c(# Fill in data here), byrow =TRUE, nrow =#fill in number of rows)table_data
Error in parse(text = input): <text>:12:0: unexpected end of input
10:
11:
^
What is the test statistic for this test?
What is the p-value?
What is your conclusion?
Homework: Grades and Classroom Type
This is the raw data for the Homework Quiz. Use it to answer the homework questions, but also create a Bar Chart using ggplot().
Question: Are the requirements for a test satisfied? Answer:
Question: What are the null and alternative hypotheses? Answer:
Question: What is the test statistic, ? Answer:
Question: How many degrees of freedom does this test have? Answer:
Question: What is the P-value? Answer:
BONUS
Categorical data analysis and visualization is usually easier to work with raw data. It’s easier to create the table and use chisq.test(), and we can also use ggplot() directly.
Sometimes we only have a summary table. Below you will find a few new functions that might help if the imported data are shaped as a summary table.
Heart Disease among Australian Women and Men
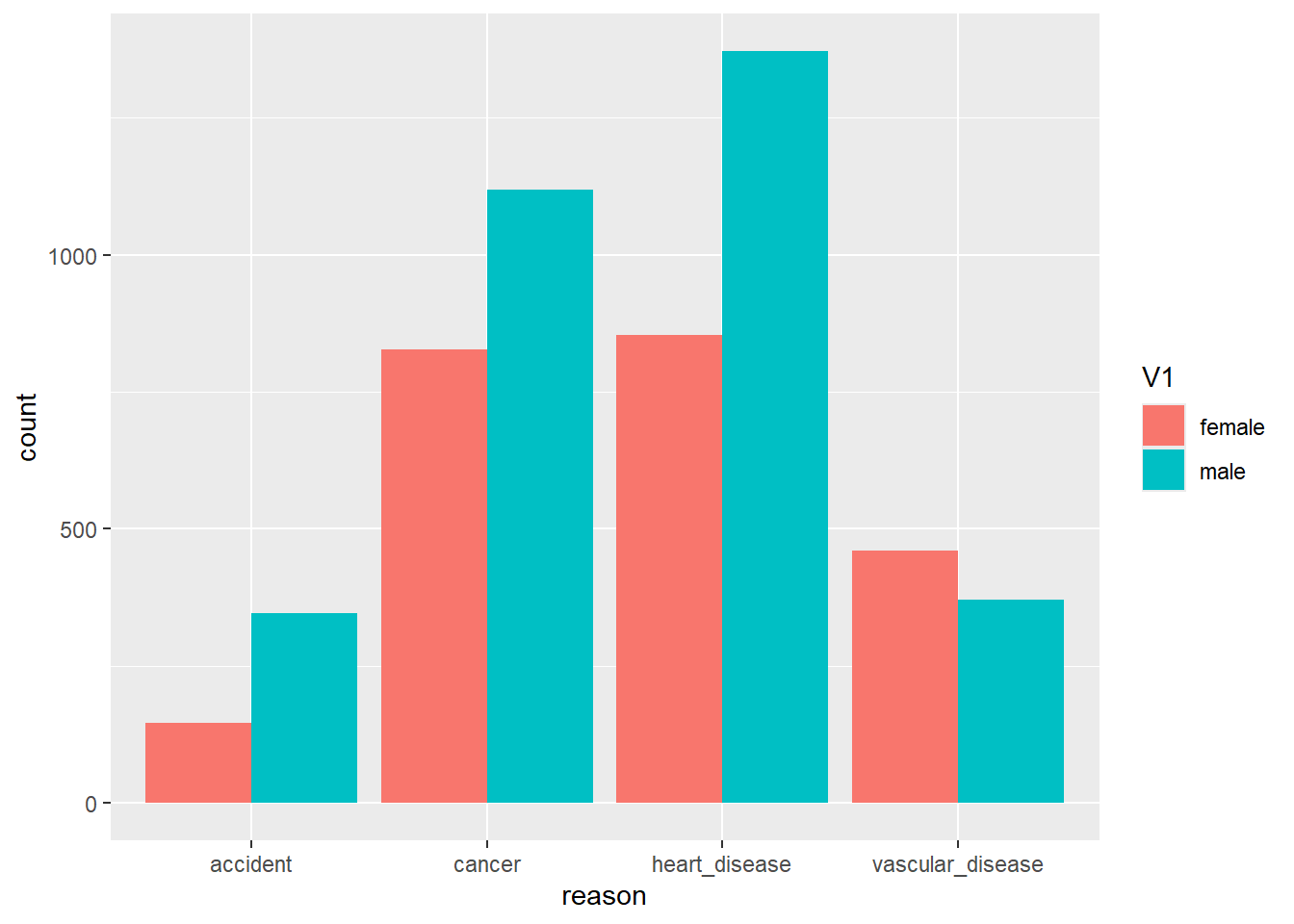
In 1982 in Western Australia, 1317 males and 854 females died of ischemic heart disease, 1119 males and 828 females died of cancer, 371 males and 460 females died of cerebral vascular disease, and 346 males and 147 females died of accidents. A medical researcher wanted to see if gender and cause of death are independent using a level of significance of 0.05.
The data read in below are a summary table of counts. One way to create a bar chart to compare heart disease deaths between men and women is to take this data and make it “longer”. This stacks the columns with count data in them and makes 2 new columns, one for the counts and one for the category of cardiovascular death.
I will comment the code below to walk through each step.
The %>% “pipe” below comes from the tidyverse library. You can think of this like making a series of steps where everything before the %>% is pushed to the next step. For example, we assign aussie_death the original data table then move the table into the pivot_long() function which is the function that stacks the data. The output of that function becomes a new data shape, aussie_death.
# Import the table dataaussie_death_table <-import("https://byuistats.github.io/M221R/Data/quiz/R/aussie_death.csv") aussie_death_table
V1 heart_disease cancer vascular_disease accident
1 female 854 828 460 147
2 male 1371 1119 371 346
# Pipe the original table into the pivot_longer() function# Pivot_longer needs to know which columns to "stack" which is input by the 'cols = ' argument.# We also need to give a name to the new column containing the count information. The 'values_to=' argument names the column that will have the values, in this case we use "count". # The 'names_to = ' argument names the column that will contain the labels of each category# Run the code and see if you can follow what happenedaussie_death <- aussie_death_table %>%pivot_longer(cols =c('heart_disease', 'cancer', 'vascular_disease', 'accident'), values_to ='count', names_to ="reason")aussie_death
# A tibble: 8 × 3
V1 reason count
<chr> <chr> <int>
1 female heart_disease 854
2 female cancer 828
3 female vascular_disease 460
4 female accident 147
5 male heart_disease 1371
6 male cancer 1119
7 male vascular_disease 371
8 male accident 346
# V1 was the default label and really represents "Gender" in this study. We could change the name or leave it as is and fix it in the graphs# When using raw data, 'geom_bar()' creates the counts automatically from the categorical columns in a raw dataset. The data in aussie_death is still a summary. If we have the counts already, then we use the `geom_col()` function and have to specify a y variable to define how high to make the bars (in our case "count")ggplot(aussie_death, aes(x = reason, y = count, fill = V1)) +geom_col(position="dodge")