Rows: 1,004
Columns: 18
$ Gender <chr> "female", "female", "female", "female", "fe…
$ Age <int> 20, 19, 20, 22, 20, 20, 20, 19, 18, 19, 19,…
$ Height <int> 163, 163, 176, 172, 170, 186, 177, 184, 166…
$ Weight <int> 48, 58, 67, 59, 59, 77, 50, 90, 55, 60, 60,…
$ Number_of_siblings <int> 1, 2, 2, 1, 1, 1, 1, 1, 1, 3, 2, 1, 10, 1, …
$ Dominant_hand <chr> "right handed", "right handed", "right hand…
$ Education <chr> "college/bachelor degree", "college/bachelo…
$ Only_child <chr> "no", "no", "no", "yes", "no", "no", "no", …
$ Fear_score <int> 38, 32, 22, 72, 36, 38, 40, 56, 64, 80, 34,…
$ Religiosity_score <int> 60, 33, 83, 50, 77, 53, 73, 60, 60, 83, 60,…
$ Smoking <chr> "never smoked", "never smoked", "tried smok…
$ Alcohol <chr> "drink a lot", "drink a lot", "drink a lot"…
$ I_live_a_healthy_lifestyle <chr> "Agree", "Neither Agree nor Disagree", "Nei…
$ I_like_music <chr> "Strongly Agree", "Agree", "Strongly Agree"…
$ Music_diversity_score <int> 33, 44, 63, 34, 51, 58, 48, 43, 38, 58, 46,…
$ Punctuality <chr> "i am always on time", "i am often early", …
$ Lying <chr> "never", "sometimes", "sometimes", "only to…
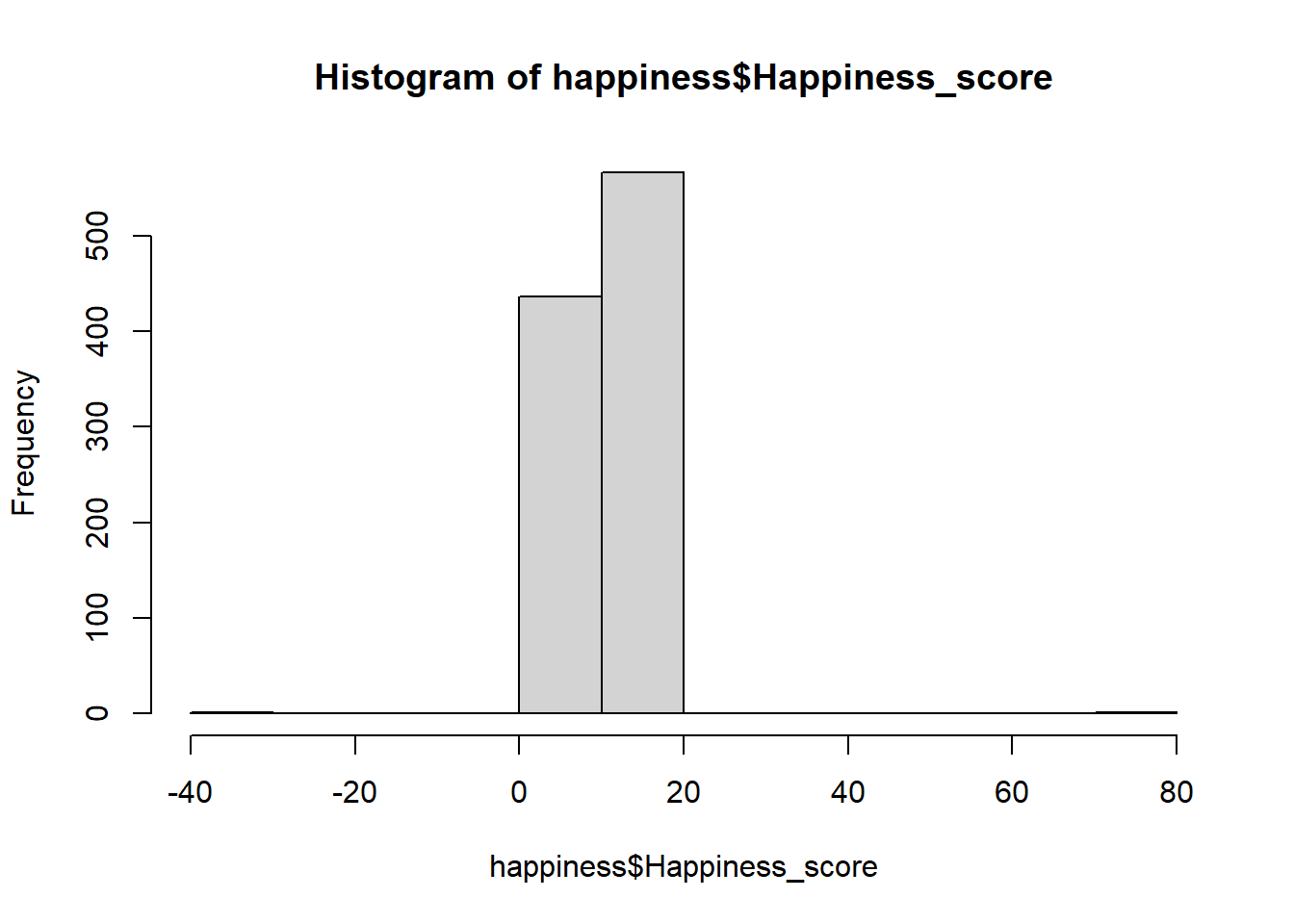
$ Happiness_score <int> 13, 10, 11, 6, 11, 10, 12, 12, 7, 11, 10, 9…