# Load libraries and data
library(rio)
library(mosaic)
library(tidyverse)
library(car)
survey <- import('https://github.com/byuistats/Math221D_Cannon/raw/master/Data/HighSchoolSeniors_subset.csv') %>% tibble()select()
Selecting Columns
Consider the High School survey data with 60 columns and 312 respondents.
It is likely that we are not interested in analyzing every column in this dataset. Many may even be useless. We can use the tidyverse function, select() to create a subset of the columns that we are primarily interested in.
Recall that we can “pipe” the raw data into tidy functions using %>%. Suppose we want to see if there are differences in reaction times (Reaction_time) for left-handed and right-handed students. We could create a more manageable dataset with only the columns of interest:
survey %>%
select(Handed, Reaction_time)# A tibble: 312 × 2
Handed Reaction_time
<chr> <dbl>
1 Left-Handed 0.349
2 Right-Handed 0.358
3 Right-Handed 0.447
4 Right-Handed 0.438
5 Left-Handed 0.542
6 Right-Handed 0.428
7 Ambidextrous 0.258
8 Right-Handed 0.427
9 Right-Handed 0.412
10 Right-Handed 0.346
# ℹ 302 more rows
Combining Tidy Functions
- Click to see how to filter out Ambitextrous participants and reaction time outliers (reaction times less than 1 seconds):
Click to see
clean <- survey %>%
filter(Handed != "Ambidextrous",
Reaction_time < 1) %>%
select(Handed, Reaction_time)
boxplot(clean$Reaction_time ~ clean$Handed, col = c(2,3), ylab = "Reaction Times", xlab="", main = "Distribution of Reaction times for \n Left and Right-hand Dominance")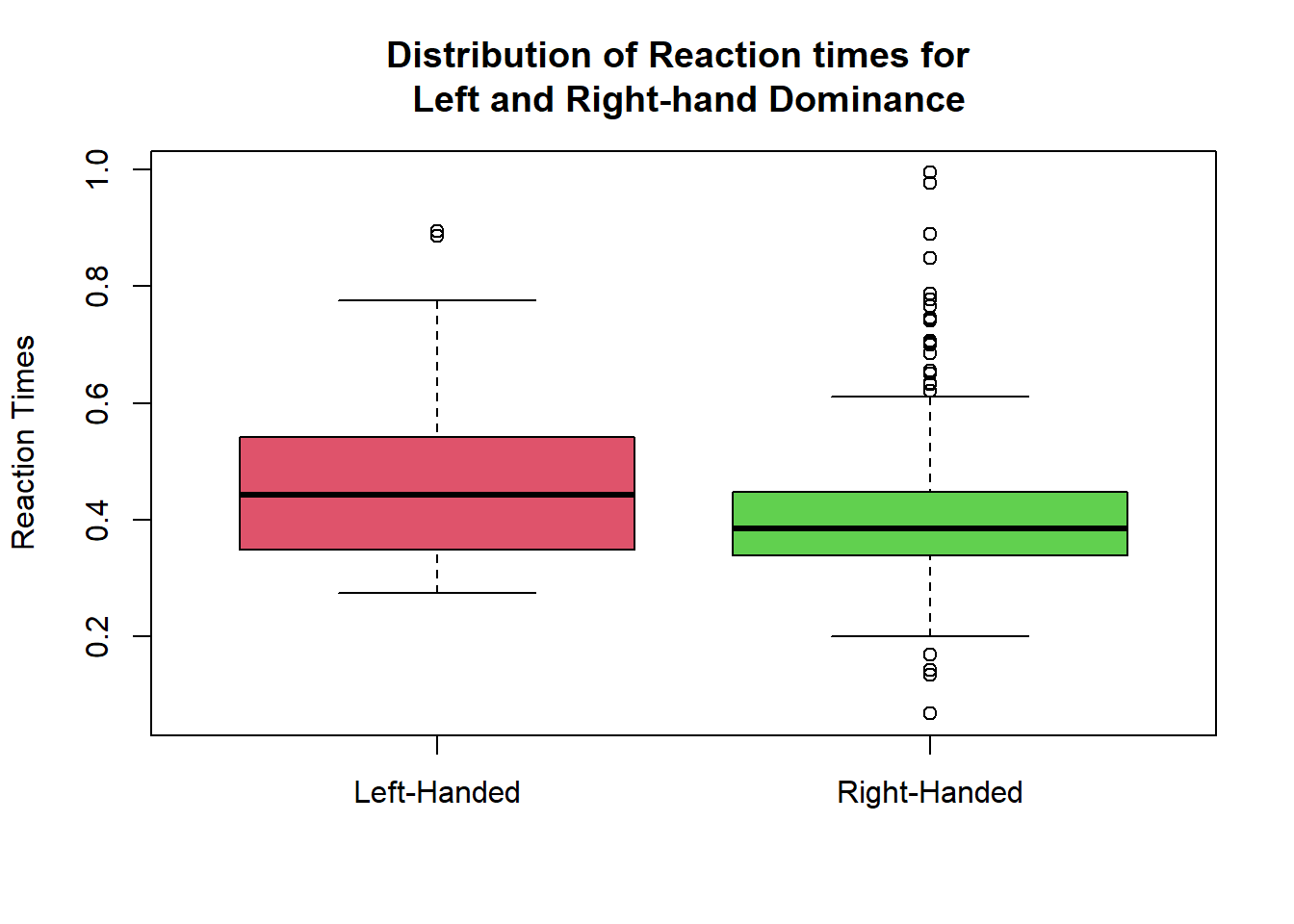
Which hand dominance appears to have quicker reaction times?