table(iris$Species)
setosa versicolor virginica
50 50 50 When we want to compare 3 or more groups, the math get’s more complicated. Analysis of Variance (ANOVA) compares how spread out the means are relative to the within group variation.
The null and alternative hypotheses are always the same for an ANOVA:
The Test Statistic for comparing more than 2 groups is called
The formula for the new test statistic,
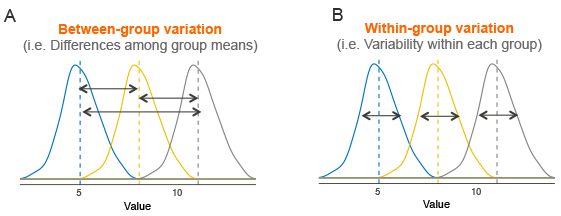
The test statistic is the ratio of the variation between groups and the average variation within groups. The further spread out the sample means are relative to the noise within the groups, the more significant the result.
Recall that the shape of the
The numerator, or between groups degrees of freedom is
The denominator, or within groups degrees of freedom is
We will get the values of both degrees of freedom directly from the R output.
Unlike the
To summarize:
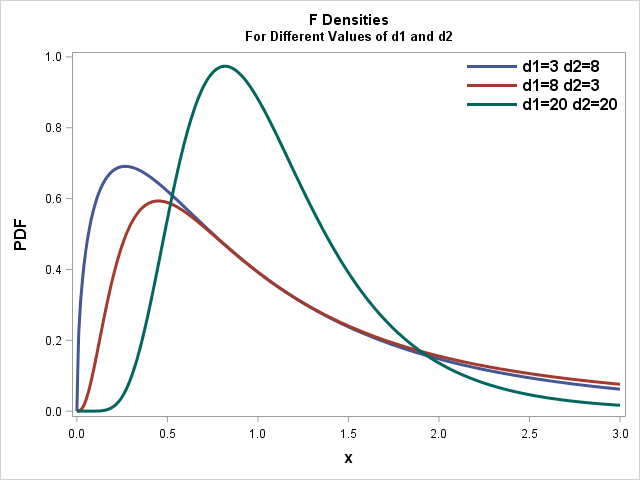
The P-value for an F-statistic is always one-tailed. The probability of observing a test statistic,
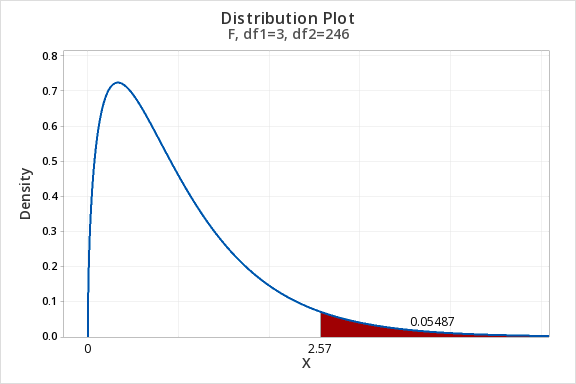
In practice, the computer calculates the test statistic, P-value, and degrees of freedom and we interpret the output as with other statistical tests.
Just as with other statistical tests we’ve done so far, the
What to check:
To check the first requirement we can compare the biggest standard deviation to the smallest. If the ratio of the biggest to the smallest is less than 2, we conclude that the population standard deviations are “equal”.
NOTE: Intuitively, this means that if the biggest standard deviation is more than twice as big as the smallest, then we might have cause for concern.
This can be checked using the standard deviations from the favstats() output (see Analysis in R below)
Residuals are defined as the difference between an observation and it’s “expected” value:
In the case of ANOVA, that means we get a residual for every observation by taking the observed value and subtracting its group mean. Once again, R will provide this for us.
For our analysis to be valid, we need to see if the residuals are normally distributed. We can do a qqPlot() of the residuals to assess this requirement.
If both requirements are met, we can trust the P-value.
Much of the syntax for ANOVA will look familiar, but we will be using a new function, aov() instead of t.test().
The aov() function by itself isn’t as useful as t.test(). However, we can use the summary() function to give us everything we need.
We typically name our output using the assignment operator <- to make it easier to get the information we would like.
The inside of aov() will look familiar, using the same ~ notation we’ve used all semester.
The generic process for performing an ANOVA is:
# Name the ANOVA output:
output <- aov(data$response_variable ~ data$categorical_variable)
# Summarise the ANOVA output to get test statistics, DF, P-value, etc:
summary(output)
Just as with the other statistical tests, ANOVA has certain requirements for us to be able to trust the P-value.
We can use favstats() to extract the standard deviations of each group, then find the ratio of the max/min to see if it is less than 2.
# extract only the standard deviations from favstats output using th `$`:
sds <- favstats(data$response_variable ~ data$categorical_variable)$sd
# Compare the max/min to 2
max(sds) / min(sds)
# if max/min < 2, then we're ok
We can assess normality of the residuals with a qqPlot(). We first need to extract the residuals from our output:
# Name the output of the aov() function `output`:
output <- aov(data$response_variable ~ data$categorical_variable)
# do a qqPlot of the residuals (observation values - group mean) that R calculates. We can use th `$` to tell R what part of the output we want to make into a qqPlot():
qqPlot(output$residuals)
If most of the points fall within the blue zone, we can be confident that the residuals are normally distributed.
For this demonstration we will be exploring the iris data. This dataset is built in to base R libraries, so we can access it without reading it in using “import”.
The iris data contains multiple measures on flowers that might be of interest to compare across species.
Let’s first compare sepal lengths between species.
How many species do we have in our dataset?
table(iris$Species)
setosa versicolor virginica
50 50 50 Create a side-by-side boxplot of species and Sepal Length.
boxplot(Sepal.Length ~ Species, data=iris, col = c(2,3,4), ylab="Sepal Length", main = "Sepal Length by Species")
Using GGPlot:
ggplot(iris, aes(x=Species, y = Sepal.Length)) +
geom_boxplot(fill=c(2,3,4)) +
theme_bw() +
labs(
y = "Sepal Length",
title = "Sepal Length by Species"
)
aov_sepal <- aov(Sepal.Length ~ Species, data=iris)
summary(aov_sepal) Df Sum Sq Mean Sq F value Pr(>F)
Species 2 63.21 31.606 119.3 <2e-16 ***
Residuals 147 38.96 0.265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Before we make a conclusion, we want to check that we can trust our output. Every statistical test has requirements that must be satisfied if we are to trust our conclusions. For ANOVA, we need to check the normality and that the variation within groups is roughly the same.
We use a QQ-plot to check for normality and the ratio of the largest to the smallest standard deviation to check “equal” variation.
# QQ plots show how closely the the residuals are to a normal distribution
qqPlot(aov_sepal$residuals)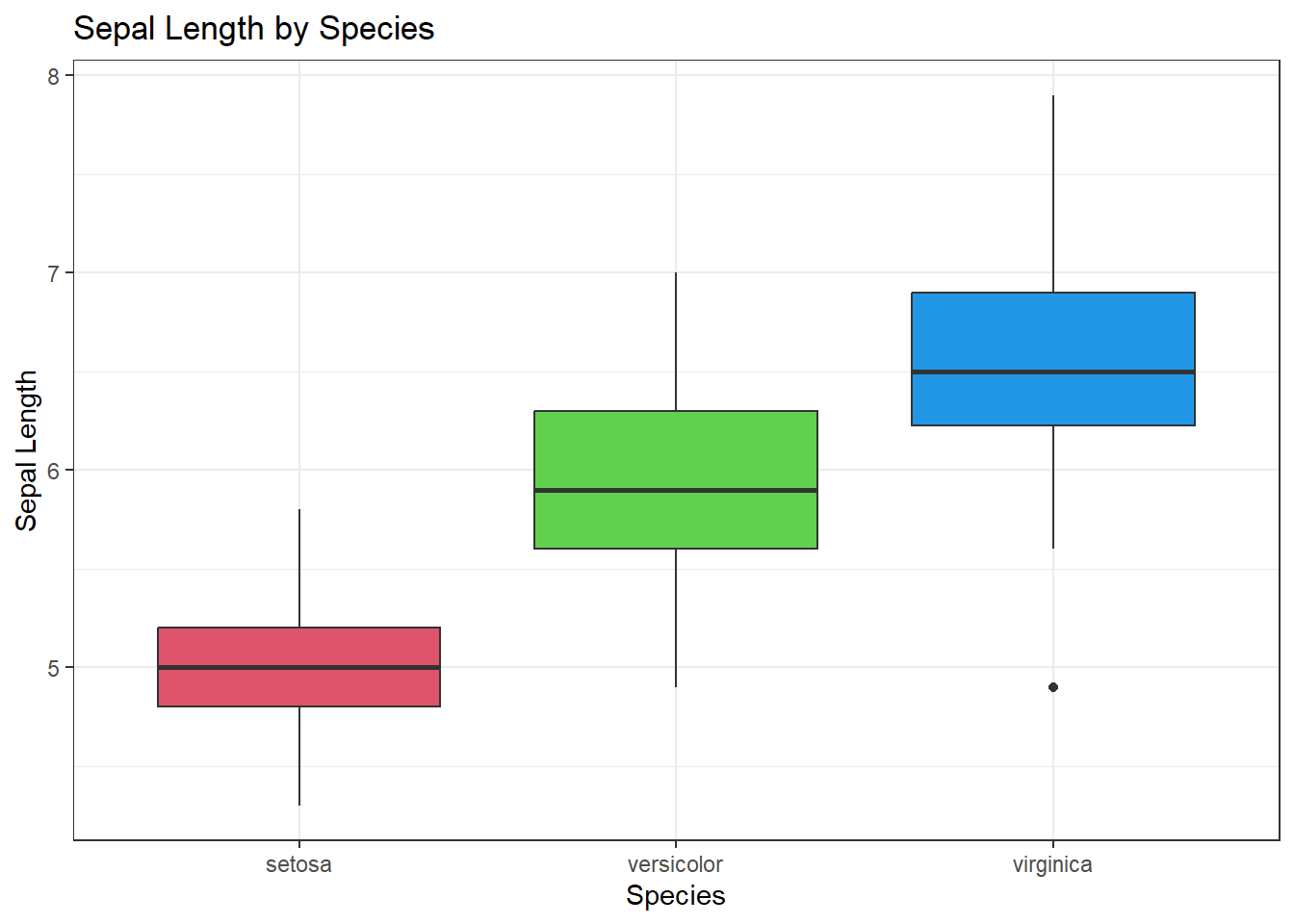
[1] 107 132# Check that there is less than a 2X difference between the largest and smallest standard deviations
# We can assign favstats()$sd to a variable to make it easier to use. Recall the "$" can also be used to extract specific output from functions
sds <- favstats(Sepal.Length ~ Species, data=iris)$sd
max(sds) / min(sds)[1] 1.803967Question: What is the F-statistics?
Answer: 119.3
Question: What are the between-groups degrees of freedom?
Answer: 2
Question: What are the within-groups degrees of freedom?
Answer: 147
Question: What is the P-value?
Answer: <2e-16
Question: What is your conclusion?
Answer: Because p is less than alpha, we reject the null hypothesis. We conclude that at least one of the means of Sepal Length is different from the other group means.
Let’s go through the same steps but compare Petal Length.
Make a side-by-side boxplot of Petal Length for each species.
State your null and alternative hypotheses:
Perform an ANOVA:
#aov_petal <- aov()
#summary(aov_petal)Question: What is the F-statistics?
Answer:
Question: What are the between-groups degrees of freedom?
Answer:
Question: What are the within-groups degrees of freedom?
Answer:
Question: What is the P-value?
Answer:
Check ANOVA requirements (max_sd/min_sd < 2, normal residuals)
Question: What is your conclusion?
Answer: