Lesson 23: Inference for Bivariate Data
Optional Videos for this Lesson
Part 1
Part 2
Part 3
Part 4
Part 5
Lesson Outcomes
By the end of this lesson, you should be able to:
- Recognize when the slope of the regression line inferential procedure is appropriate
- Create numerical and graphical summaries of the data
- Perform a hypothesis test for the slope of the regression line using
the following steps:
- State the null and alternative hypotheses
- Calculate the test-statistic, degrees of freedom and P-value of the test using software
- Assess statistical significance in order to state the appropriate conclusion for the hypothesis test
- Check the requirements for the hypothesis test
- Create a confidence interval for the slope of the regression line
using the following steps:
- Calculate a confidence interval using software
- Interpret the confidence interval
- Check the requirements of the confidence interval
- Calculate the residual value for a given observation
- Interpret the residual value
Theory of Simple Linear Regression
When we compute an estimated regression equation, we assume that there is some true equation that describes the relationship between the \(X\)-variable and the mean value of \(Y\). This equation is unknown to us. In particular, we don’t know what the coefficients are in this equation. In the estimated regression equation, we used \(b_0\) and \(b_1\) to represent the \(Y\)-intercept and slope, respectively. These two coefficients are estimates of the unknown regression coefficients in the true equation. We will use the Greek letter \(\beta\) (pronounced “beta”) to denote these true unknown coefficients.
The true regression line is written as: \[ \textrm{Expected value of }~Y = \beta_0 + \beta_1 X \] where \(\beta_0\) and \(\beta_1\) are parameters. These are unknown constants representing the true values for the population.
We know that \(Y\) will not fall exactly on this line. There will be some randomness in the observed values of \(Y\). So, we add a term, called the error term, to this equation. This is a random variable, and we denote it by the Greek letter \(\epsilon\) (pronounced “epsilon”.) The true regression equation is: \[ Y = \beta_0 + \beta_1 X + \epsilon \] where \(\beta_0\) and \(\beta_1\) are parameters, and \(\epsilon\) is a (normal) random variable.
Checking Requirements of Simple Linear Regression
In order to do hypothesis tests and confidence intervals using a regression line, we need to be sure that certain conditions are satisfied. There are five requirements for a linear regression model:
- There is a linear relationship between \(X\) and \(Y\).
- The error term (\(\epsilon\)) is normally distributed.
- The variance of the error terms is constant for all values of \(X\).
- The \(X\)’s are fixed and measured without error. (In other words, the \(X\)’s can be considered as known constants.)
- The observations are independent.
These must be satisfied in order to conduct a hypothesis test or create confidence intervals involving regression lines.
We will illustrate the process of checking requirements using the estuarine crocodile data.
Scatterplot
To check requirement 1, we do two things. The first is to make a scatterplot and to visually check to see if there is a linear relationship between \(X\) and \(Y\). This has been referred to as a “hot dog” shape in the data.
We want to make sure that there is no distinct curvature or other nonlinear characteristics. This is simply a visual check of the data.
Consider the scatterplot of the estuarine crocodile data EstuarineCrocodile(Modified).xlsx:
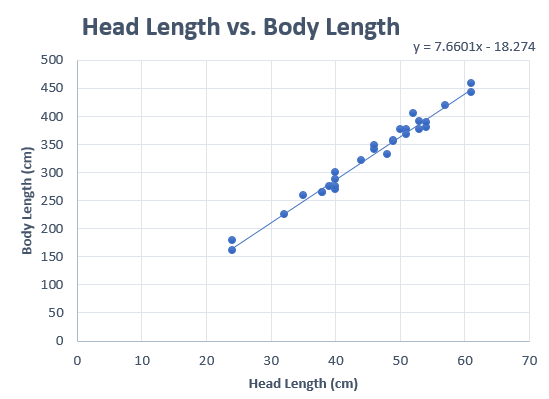
Notice how the data follow a linear shape. This data set shows a particularly strong linear relationship. In many cases, the data will show more spread than is illustrated here.
Residuals
The residual for an observation is defined as the difference between the observed value of \(Y\) and the value that would have been predicted by the regression line. As an equation, this is expressed as: \[ Residual = Y - \hat Y = Y - (b_0 + b_1 X) \]
It is tedious to calculate the residuals by hand, but software can be used to find the residuals.
To find the residuals in Excel, do the following:
- Open Math 221 Statistics Toolbox and click on the “Linear Regression” tab
- Copy and Paste the dependent (or response) variable into the “Y” column (Column B). The dependent variable (or response variable) is the thing you are trying to predict. Often it is the more difficult/expensive variable to measure.
- Copy and paste the independent (or explanatory) variable into the “X” column (Column A).
- Your residuals will then be calculated in column Y of the Excel
Spreadsheet.
Residual Plot
The residual is calculated for each data point, so you have one residual for every observation in the data set. It is hard to use so many numbers to make decisions. How do you comprehend so much information at once? To help us understand the information in the residuals, we make what is called a residual plot. A residual plot is a scatterplot where the \(X\)-axis shows the independent variable (\(X\)) and the \(Y\)-axis presents the residuals for each value of \(X\).
To make a residual plot in Excel do the following:
Once the explanatory and response variables are entered into the correct columns in the Math 221 Statistics Toolbox spreadsheet, you are given a scatter plot of residuals starting in cell S4, to the right of the hypothesis testing section.
To create a residual plot on your own, you can highlight columns X and Y, then click on the Insert Ribbon, and then click on “Scatter” (or the icon that looks like a scatter plot). You want the first choice (Scatter with only markers), so select the first scatter plot choice.
The following image shows the residual plot for the estuarine crocodile data.
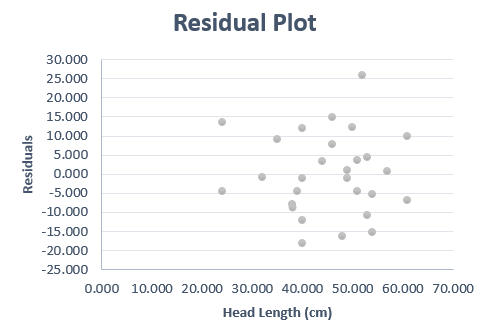
This residual plot shows random scatter. There is no obvious pattern in the data. If linear regression is appropriate, then the residual plot will show no patterns and will consist of random scatter. If there is a pattern in the residuals, it suggests that linear regression is not appropriate.
There are several patterns that could arise in a residual plot:
- Curvature If the residual plot shows curvature, that suggests that the data are not linearly related.
- Megaphone A megaphone shape occurs when points tend to be close together on one side of the graph and farther apart on the other side of the graph. If there is a megaphone shape apparent in the residuals, it suggests that the variance of the error terms is not constant for all values of \(X\). It suggests that there is a difference in the spread of the residuals depending on the value of \(X\).
- Outliers If there are outliers in the residual plot, that suggests that the error terms are not normally distributed. This should also be apparent in the scatterplot or histogram of the residuals.
Histogram of the Residuals
Once the residuals have been calculated in Excel, we can assess if they are normally distributed using a histogram. If the shape of the histogram of residuals does not show a distinct departure from a normal shape, we conclude the requirement of normal residuals has been met.Don’t forget that you may need to try out various histograms with different number of bins to get a feel for the shape of the distribution of residuals.
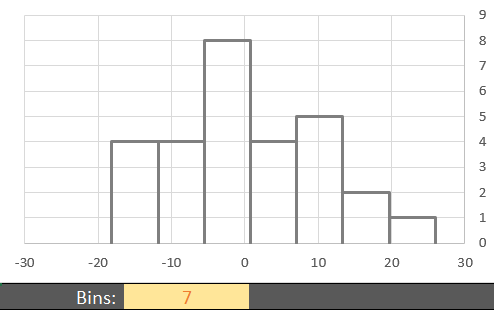
The histogram of the residuals using 7 bins does not show a distinct or extreme departure from a normal shape. We do not have evidence of nonnormality in the residuals. We conclude that the residuals are normally distributed. In more advanced classes you will use a tool called a Q-Q plot to assess whether residuals are normally distributed.
Requirements Summary
The following table describes how to check each of the requirements above.
|
Requirement |
How to Check |
What you hope to see |
|
|---|---|---|---|
|
1. |
Linear Relationship |
Scatterplot |
“Hot dog” shape |
|
Residual Plot |
No pattern in the residuals |
||
|
2. |
Normal Error Term |
Histogram of the Residuals |
A shape that is approximately normal |
|
3. |
Constant Variance |
Residual Plot |
No megaphone shape in the residuals |
|
4. |
\(X\)’s are Known |
Cannot be checked directly |
\(X\)’s should be measured |
|
5. |
Observations are |
Cannot be checked directly |
Knowing the value of one of the \(Y\)’s |
If these requirements are met, then it is reasonable to assume that the use of regression with the data is appropriate.
Hypothesis Test for Regression Coefficients
Estuarine Crocodiles
We want to know if there is a linear relationship between \(X\) and \(Y\). To test for this, we need to determine if the slope is different from zero. If the slope is zero, then that suggests that there is no linear relationship between the two variables. If the slope is not zero, that suggests that there is a linear relationship between the two variables.
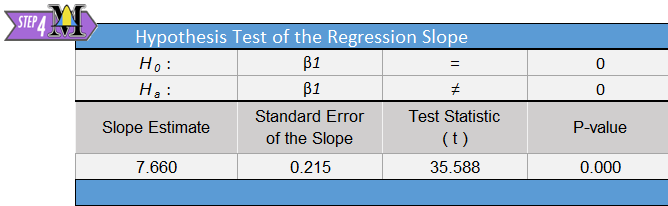
The regression output will include all the calculations you need to conduct a hypothesis test for the regression slope:
In this course, we will test if the true slope is different from zero. If the slope equals zero, then the regression line reduces from: \[Y = \beta_0 + \beta_1 X + \epsilon\]
to: \[Y = \beta_0 + \epsilon\]
In other words, the independent variable \(X\) does not affect the value of the dependent variable \(Y\).
The null and alternative hypotheses for this test are: \[ \begin{array}{ll} H_0: & \beta_1 = 0\\ H_a: & \beta_1 \ne 0\\ \end{array} \]
We will assume the \(0.05\) level of significance.
The relevant summary statistics include the sample size and the estimated regression equation (\(\hat Y = b_0 + b_1 X\)). For the estuarine crocodile data, we get: \[ \begin{array}{c} n=28 \\ \hat Y = -18.274 + 7.660 X \\ \end{array} \]
The test statistic follows a \(t\)-distribution. We are conducting a test for the slope. The information related to the slope is given in the second row of the “Coefficients” table, which is labeled “Head Length (cm)”. Looking across the second row, we find the value of \(t\) is given as 35.588. \[ t=35.588 \]
This is a tremendously large value for t. This indicates that there is a lot of evidence against the null hypothesis.
Remember, the \(t\) distribution has one number describing its degrees of freedom. The degrees of freedom for this test is not shown on the Excel sheet, but is easy to calculate by hand. Because we used the dataset to estimate two population parameters (a slope and a y-intercept) we have used two degrees of freedom. There are 28 observations in our dataset. The degrees of freedom equals \(28-2 = 26\) for the estuarine crocodile data. \[ df= 28-2 = 26 \]
With a test statistic of \(t=35.588\), we get a very small \(P\)-value, “0.000” as shown in cell Q9.
Assuming \(\alpha=0.05\), we reject the null hypothesis since the \(P\)-value is less than the level of significance. There is sufficient evidence to suggest that there is a linear relationship between the head length and the body length of estuarine crocodiles.
It was appropriate to conduct this analysis, since the requirements of simple linear regression were satisfied.
Manatees
Here is an excerpt from the output for the Manatees.xlsx data set:

The null and alternative hypotheses for this test are: \[ \begin{array}{ll} H_0: & \beta_1 = 0\\ H_a: & \beta_1 \ne 0\\ \end{array} \]
The relevant summary statistics include the sample size and the estimated regression equation (\(\hat Y = b_0 + b_1 X\)). \[ \begin{array}{c} n=35 \\ \hat Y = -42.542 + 0.129 X \\ \end{array} \]
The test statistic follows a \(t\)-distribution.
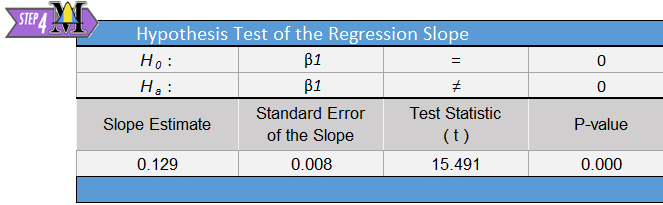
Remember, we are conducting a test for the slope, so the information we need is given in the block of output labeled “Hypothesis Test of the Regression Slope”. We find the value of \(t\) is given as 15.491. \[ t=15.491 \]
Think about this result. Is this a large or a small value for \(t\)? What does this say about the conclusion to our test?
Remember, the \(t\) has one number
describing its degrees of freedom. For this test, the degrees of freedom
\(35-2 = 33\). We subtract two from the
total number of observations because we estimated a 2 population
parameters for the line: a y-intercept and a slope.
\[
df=33
\]
With a test statistic of \(t=15.491\) and \(33\) degrees of freedom, we get a very small \(P\)-value. The value is so small that when we round to just three decimal places, the \(P\)-value appears to be zero.
Assuming \(\alpha=0.05\), our decision rule is to reject the null hypothesis, since the \(P\)-value is less than the level of significance. There is sufficient evidence to suggest that there is a linear relationship between the number of powerboats registered in Florida and the number of manatees killed by powerboats. This conclusion fits our intuition. If there are more boats on the water, it seems plausible that this will affect the number of manatees killed. If any statistical conclusion is counterintuitive, you should always be very wary!
Confidence Intervals for Regression Coefficients
Manatees
We are often interested in the range of plausible values for the true regression coefficients. We can create a confidence interval for the slope and the \(Y\)-intercept in Excel.
To find the residuals in Excel, do the following:
- Open Math 221 Statistics Toolbox and click on the “Linear Regression” tab
- Copy and Paste the dependent (or response) variable into the “Y” column (Column B). The dependent variable is also known as the response variable. It is the thing you are trying to predict. Often it is the more difficult/expensive variable to measure.
- Copy and paste the independent (or explanatory) variable into the “X” column (Column A).
- You can change the confidence level in cell N12.
- The confidence interval for the slope is found in cells P15 and Q15.
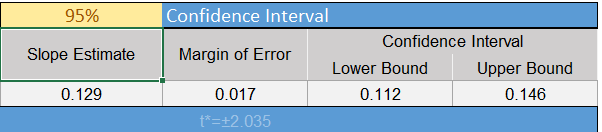
In this case, the 95% confidence interval for the true slope of the regression line relating the number of thousand powerboats registered in Florida to the number of manatees killed is \((0.112, 0.146)\). Remember the slope is the amount that \(Y\) is expected to change if \(X\) changes by one unit. Also, recall that \(X\) is given in terms of thousands of powerboats registered. If an additional one thousand powerboats are registered (one unit increase in \(X\),) we are 95% confident that the number of manatees killed will increase between 0.112 and 0.146. Or in other words, if 100 thousand additional powerboats are registered in Florida, we expect 11.2 to 14.6 manatees will be killed.
Though the Math221 Excel toolbox does not compute a 95% confidence interval for the \(Y\)-intercept, many softwares do. The 95% confidence interval for the \(Y\)-intercept is \((-55.460, -29.623)\). We are 95% confident that the expected number of manatees that will be killed if there are zero powerboats registered in Florida is between \(-55.5\) and \(-29.6\). This is illogical. There cannot be a negative number of manatees killed. The \(Y\)-intercept is not interpretable.
Sometimes the \(Y\)-intercept makes sense in the context of the problem, but in many cases it is just used to get the best fit for the regression equation.
Estuarine Crocodiles
We can compute a 95% confidence interval for the estuarine crocodile data in a similar manner.
- Find a 95% confidence interval for the slope of the regression line relating the head lengths and body lengths of estuarine crocodiles.
- Interpret the confidence interval you created in the previous problem.
Summary
The unknown true linear regression line is \(Y=\beta_0+\beta_1X\) where \(\beta_0\) is the true y-intercept of the line and \(\beta_1\) is the true slope of the line.
A residual is the difference between the observed value of \(Y\) for a given \(X\) and the predicted value of \(Y\) on the regression line for the same \(X\). It can be expressed as: \[ Residual = Y - \hat Y = Y - (b_0 + b_1 X) \]
To check all the requirements for bivariate inference you will need to create a scatterplot of \(X\) and \(Y\), a residual plot, and a histogram of the residuals.
We conduct a hypothesis test on bivariate data to know if there is a linear relationship between the two variables. To determine this, we test the slope (\(\beta_1\)) on whether or not it equals zero. The appropriate hypotheses for this test are: \[ \begin{array}{1cl} H_0: & \beta_1=0 \\ H_a: & \beta_1\ne0 \end{array} \]
For bivariate inference we use software to calculate the sample coefficients, residuals, test statistic, \(P\)-value, and confidence intervals of the true linear regression coefficients.
Copyright © 2020 Brigham Young University-Idaho. All rights reserved.