Lesson 13: Inference for the Difference of Two Means (Two Independent Samples)
Optional Videos for this Lesson
Part 1
Part 2
Part 3
Part 4
Part 5
Lesson Outcomes
By the end of this lesson, you should be able to do the following.
- Recognize when the difference of means (two independent samples) inferential procedure is appropriate
- Create numerical and graphical summaries of the data
- Perform a hypothesis test for the difference of means (two
independent samples) using the following steps:
- State the null and alternative hypotheses
- Calculate the test-statistic, degrees of freedom and P-value of the test using software
- Assess statistical significance in order to state the appropriate conclusion for the hypothesis test
- Check the requirements for the hypothesis test
- Create a confidence interval for the difference of means (two
independent samples) using the following steps:
- Calculate a confidence interval using software
- Interpret the confidence interval
- Check the requirements of the confidence interval
Independent Samples Versus Paired Data
In the previous reading Lesson 12: Inference for Two Means: Paired Data we studied confidence intervals and hypothesis tests for the difference of two means, where the data are paired. One example of paired data is pre- and post-test scores, such as Mahon’s weight loss study. Another example is paired comparisons, like the nosocomial infection study. How can you tell if data are paired? The key characteristic of dependent samples (or matched pairs) is that knowing which subjects will be in Group 1 determines which subjects will be in Group 2. The data for each subject in Group 1 is paired with the data for a corresponding subject in Group 2. In the case of the weight loss study, the same subject provided weight data for both groups: once in the pre-test (group 1) and once in the post-test (group 2).
In contrast to dependent samples, two samples are independent if knowing which subjects are in Group 1 tells you nothing about which subjects will be in Group 2. With independent samples, there is no pairing between the groups. Suppose you want to compare the incomes of men and women in the general population. A random sample of men would be collected, and each would be asked to report their income. Similarly, a random sample of women would be drawn, and they would also be asked to report their income. Notice that the groups are independent. Knowing the names of the men who are selected tells you nothing about which women would be selected. This is an example of independent samples.
We can compare the mean income of men to the mean income of women using the procedures of this section. We will conduct hypothesis tests and compute confidence intervals for the difference in the true population means of two groups (\(\mu_1 - \mu_2\)).
Some students make the association that samples are independent if they do not affect each other. This is a false notion. Instead, remember that samples are independent if knowing who was selected for Group A tells you nothing about who will be selected for group B.
Hypothesis Tests

Reading Practices of Children with Developmental or Behavioral Problems
Is there a difference in the amount of reading done by children with problematic behavior compared to other children?

Summarize the relevant background information
Researchers led by Arlene Butz published a study on the reading practices of children . They wanted to know if there was a difference in the reading practices of children with developmental or behavioral problems (the DEV group or Group 1) compared to children in the general population who do not have developmental problems (the GEN group or Group 2.) One of the factors they considered was the number of nights each week that the children participated in reading in the home. Data representative of their results are given in the file ReadingPractices.xlsx.
State the null and alternative hypotheses and the level of significance
The null hypothesis is that there is no difference in the mean number of nights each week in which the two groups of children participate in reading in the home. The alternative hypothesis is that there is a difference in the mean number of nights that the children in the two groups participate in reading in the home. These hypotheses are expressed mathematically as: \[ \begin{align} H_0: &~~ \mu_1 = \mu_2 \\ H_a: &~~ \mu_1 \ne \mu_2 \end{align} \]
We will use the \(\alpha = 0.05\) level of significance.

Describe the data collection procedures
A group of children were enrolled in the study. Children who were identified to have developmental or behavioral problems were labeled as Group 1 (the DEV group). Children who did not display developmental or behavioral problems were labeled as Group 2 (the GEN group). A survey was administered to a parent of each of the children. One of the questions on the survey asked the number of nights that either their child read or that they read to their child during the week. This data is found in the file ReadingPractices.xlsx.
- For which group do you think the mean number of nights of reading will be higher?
- Do the data published by Arlene Butz and her colleagues represent paired data or independent samples? How can you tell?

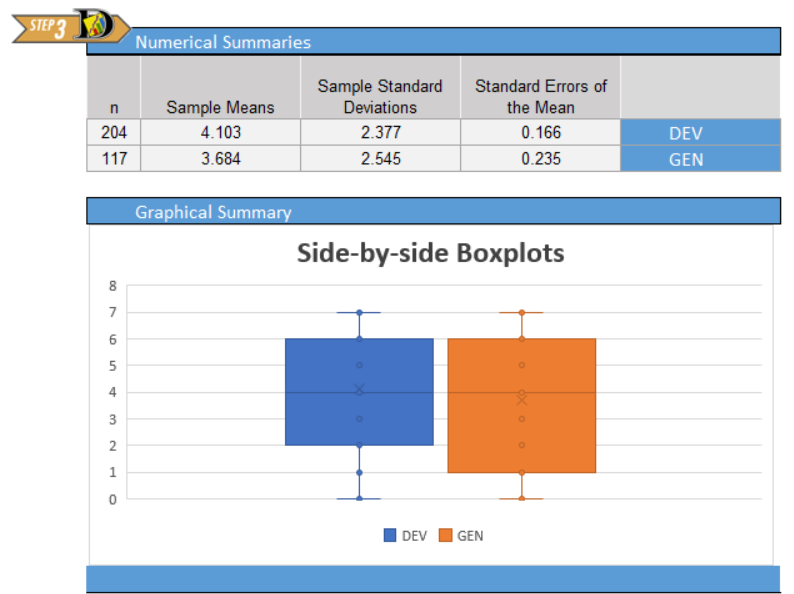
Give the relevant summary statistics
We will use \(\bar x_1\) to denote the mean of Group 1. Similarly, we use \(s_1\) and \(n_1\) for the standard deviation and sample size of Group 1. For Group 2, we indicate the mean, standard deviation and sample size with the symbols: \(\bar x_2\), \(s_2\), and \(n_2\), respectively.
- Find the mean, standard deviation and sample size for the two groups, separately. In other words, find \(\bar x_1\), \(s_1\), \(n_1\), \(\bar x_2\), \(s_2\), and \(n_2\).
4.Based on the summary statistics (means, standard deviations, and sample sizes) for the two groups, does the true mean number of nights each week that the children engage in reading seem to differ significantly between the DEV and GEN groups?
Show/Hide Solution
Make an appropriate graph to illustrate the data
There are two populations, and it is important to illustrate both of them separately. It is not sufficient to combine the groups and to produce a single graph. This would obscure the differences in the groups.
To visualize the distributions of the two sample simultaneously:
Use the “Two-sample t Test” tab of the Math 221 Statistics Toolbox to create separate histograms, one for each group. You can enter a label for Group1 in L7, and a label for Group 2 in L8.
 - Then, choose “Paste
Special” - A list of options will appear; from this list choose one of
the “Picture” options, such as “Picture (PNG)” - This will paste a
static image of the graph in the Word document, which you can move
around or shrink as desired - You should create a title for the graph
and place it above the graph in your document
- Then, choose “Paste
Special” - A list of options will appear; from this list choose one of
the “Picture” options, such as “Picture (PNG)” - This will paste a
static image of the graph in the Word document, which you can move
around or shrink as desired - You should create a title for the graph
and place it above the graph in your document
Verify the requirements have been met
There are two requirements that need to be checked when conducting a hypothesis test for two means with independent samples:
- A simple random sample was drawn from each of the populations
- \(\bar x\) is normally distributed for each group
Remember, the second requirement will be satisfied if the original populations are normally distributed or if the sample sizes are large. In this example, both groups have a large sample size, so the second requirement is met.
We will assume the data from the study is a representative sample from each of the populations.
Give the test statistic and its value
The test statistic for a hypothesis test comparing two means with independent samples is a \(t\). We will use software tools to conduct the hypothesis test for two means with independent samples:
Hypothesis Test
The following instructions will help you conduct a hypothesis test for two means with independent samples in Excel.
Use the file Math 221 Statistics Toolbox to do the following:
- Click on the tab labeled “Two-sample t-test”
- Paste the data from the first group in the appropriate part of Column A
- Paste the data for the second group in the designated part of Column B
- Click on the drop-down menu in cell Q6 and choose the appropriate alternative hypothesis
For the Reading Practices example, we choose “Not equal to”
- The test statistic, \(t\), is given in cell P10
- The (approximate) degrees of freedom are presented in cell Q10
- The \(P\)-value is reported in cell
R10
Now, we will apply these steps to the data from the study on the reading practices of children with developmental and behavioral problems.
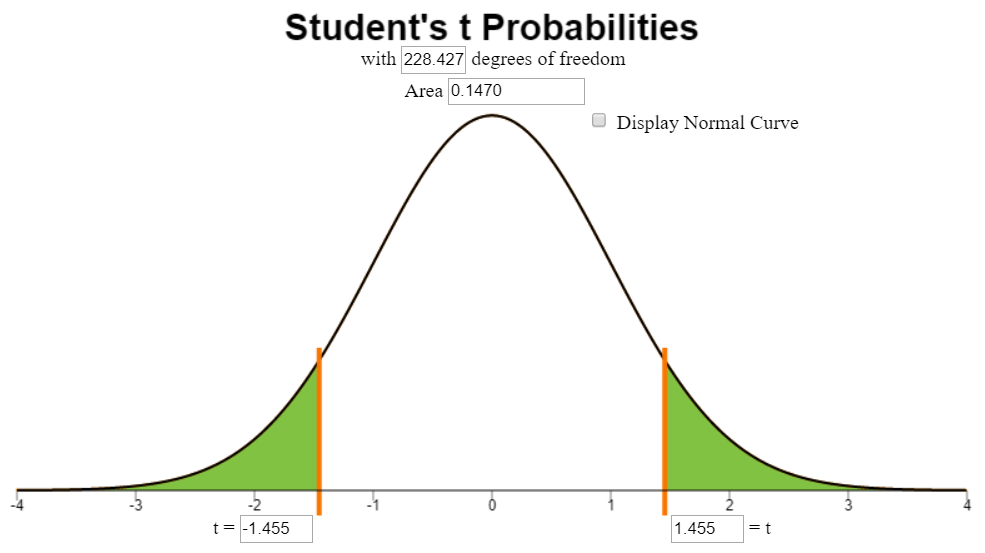
If you assign the DEV group to be Group 1, and the GEN group as Group 2, then the test statistic will be:
\[ t = 1.455 \]
If the group labels are switched, then the \(t\) statistic will have the opposite sign.
State the degrees of freedom
The degrees of freedom are given as: \[df = 228.427\]
You will notice that this is not a whole number. This is called the Satterthwaite approximation for the degrees of freedom. Do not worry that this is not an whole number. Just record the value as it is given to you in the software.
Mark the test statistic and \(P\)-value on a graph of the sampling distribution
The image below represents the area under the curve of a \(t\)-distribution.
Find the \(P\)-value and compare it to the level of significance
From the output, we find that the \(P\)-value is 0.147.
\[ P\text{-value}=0.147 > 0.05 = \alpha \]
State your decision
Since the \(P\)-value is greater than the level of significance, we fail to reject the null hypothesis.

Present your conclusion in an English sentence, relating the result to the context of the problem
There is insufficient evidence to suggest that there is a difference in the mean number of nights children with developmental / behavioral disabilities read compared to children in the general population.
World Cup Heart Attacks
Do intense sporting events increase the probability of a person having a heart attack? We will consider this question in the next example.

Summarize the relevant background information
The FIFA Football (Soccer) World Cup is held every four years and is one of the biggest sporting events in the world. In 2006, Germany hosted the World Cup. A study was conducted by Dr. Wilbert-Lampen, et. al. to determine if the stress of viewing a soccer match would increase the risk of a heart attack or another cardiovascular event.
We will use the data on cardiovascular problems during the World Cup to test the hypothesis that the mean number of cardiovascular events is greater during the World Cup than during the control period.
State the null and alternative hypotheses and the level of significance
Let Group 1 be days in the Control Period and let Group 2 represent days during the 2006 World Cup. We are testing whether the mean number of cardiovascular events is greater during the World Cup than during the control period. So, the alternative hypothesis will be one-sided.
\[ \begin{align} H_0: & ~~ \mu_1=\mu_2 \\ H_a: & ~~ \mu_1 < \mu_2 \end{align} \]
We will use the 0.01 level of significance.
Describe the data collection procedures
The 2006 World Cup was held from June 9, 2006 to July 9, 2006. The number of patients suffering cardiovascular events (e.g. heart attacks) was obtained from medical records of patients in the Greater Munich (Germany) area during this time period. To provide a control group, counts of patients suffering cardiovascular events was recorded from May 1 to June 8 and July 10 to July 30, 2006, as well as May 1 to July 30 in 2003 and 2005. The year 2004 was avoided, due to the European Soccer Championships held in Portugal. These data were extracted from Figure 1 in the article by Wilbert-Lampen, and are given in the file WorldCupHeartAttacks.xlsx.
- Give the relevant summary statistics
- Make an appropriate graph to illustrate the data
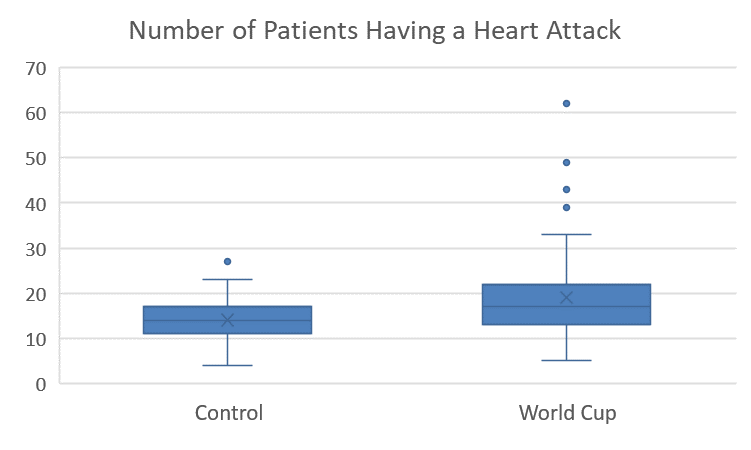
- Verify the requirements have been met
- Give the test statistic and its value
- State the degrees of freedom
- Mark the test statistic and \(P\)-value on a graph of the sampling distribution
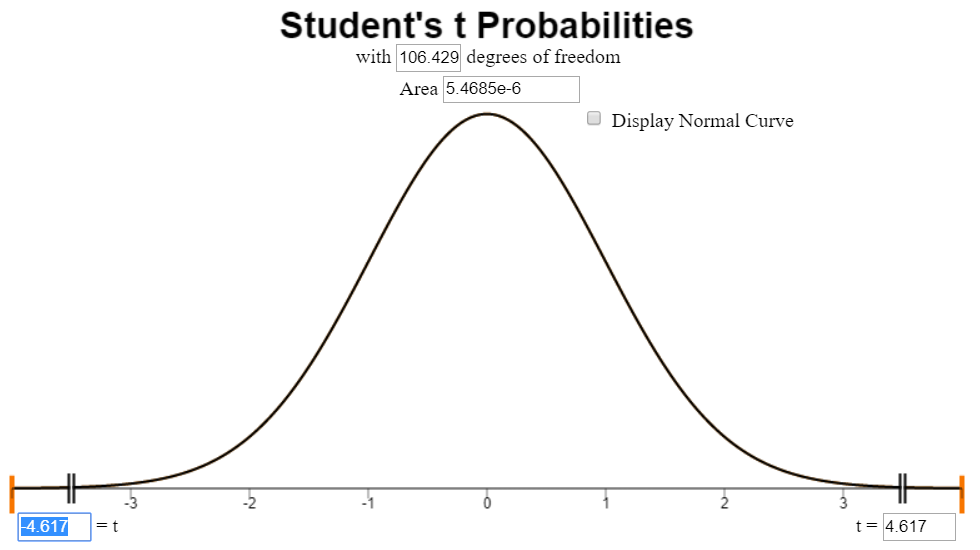
- Find the \(P\)-value and compare it to the level of significance
- State your decision
- Present your conclusion in an English sentence, relating the result to the context of the problem
Theory of Statistics
In this course, we do not go very deep into statistical theory. For those students who are interested, there is a lot of theory undergirding statistical practice.
An important theoretical issue relates to this hypothesis test. If the variances of the two groups are equal, then traditional statistical theory suggests that you combine or pool the information about the variance in the two groups. If the variances are not equal, you do not combine the information about the spread. These two techniques usually lead to slightly different values for the \(t\)-statistic, degrees of freedom, and \(P\)-value.
If the variances observed in the sample data are very different from each other, you assume unequal variances and do not pool the data. However, if the variances are very similar to each other, the results of the two procedures will be nearly identical. In this case, it does not really matter which you choose.
So, if the variances differ significantly, we should not assume equal variances. If the variances do not differ significantly, it doesn’t really matter if you assume equal variances or not. So, for this course, we will never assume the variances are equal. Stated, differently, we always assume unequal variances in this course. This provides a consistent framework for your learning.
Confidence Intervals
Reading Practices of Children with Developmental or Behavioral Problems
Summarize the relevant background information
Researchers led by Arlene Butz published a study on the reading practices of children [55]. They wanted to know if there was a difference in the reading practices of children with developmental or behavioral problems (the DEV group) compared to children in the general population who do not have developmental problems (the GEN group.) One of the factors they considered was the number of nights each week that the children participated in reading in the home.
We can use a 95% confidence interval to compare the difference between the true mean number of nights children in the DEV group participated in reading compared to children in the GEN group. We are trying to find an estimate for the difference in the true means of the two groups. Using math symbols, we want to estimate the value of \(\mu_1 - \mu_2\). The confidence interval gives a range of plausible values for the unknown parameter \(\mu_1 - \mu_2\).
Notice that if \(\mu_1 - \mu_2 = 0\), if we add \(\mu_2\) to both sides of the equation, we get: \(\mu_1 = \mu_2\). Extending that idea, if zero is in the confidence interval, then it is plausible that \(\mu_1 = \mu_2\). If zero is in the confidence interval, we conclude that there is no significant difference between the mean number of nights the children in the two groups read at home.
Software can be used to compute the confidence interval for a difference of two means with independent samples.
Describe the data collection procedures
In the study by Arlene Butz, et.al., on the reading practices of children, the researchers wanted to determine if there was a difference in the mean number of nights children read in the two groups (DEV and GEN). A survey was given to the child’s caretaker (usually a parent). This survey included questions about the child’s development and behavior. The survey also asked the number of nights each week that the child participated in reading in the home. Data representative of their results are given in the file ReadingPractices.xlsx.
Give the relevant summary statistics
Using Excel, we compute the following:
| DEV Group Group 1 | GEN Group Group 2 | |
|---|---|---|
| Mean: | \(\bar x_1 = 4.1\) | \(\bar x_2 = 3.7\) |
| Standard Deviation: | \(s_1 = 2.4\) | \(s_2 = 2.5\) |
| Sample Size: | \(n_1 = 204\) | \(n_2 = 117\) |
Make an appropriate graph to illustrate the data
Verify the requirements have been met
The sample size is large enough in both groups respectively, so we can be assured the sampling distribution of the mean for each group is normal.
Find the confidence interval
In this example, we compute the 95% confidence interval for the difference in the mean number of nights the children in the DEV and GEN groups are reading. To obtain a confidence interval for the difference in two means with independent samples, follow these steps:
To compute a 95% confidence interval for two independent samples in Excel:
- Open the file Math 221 Statistics Toolbox
- Click on the tab labeled, “Two-sample t-test”
- Paste the data for the first group in the appropriate place of column A
- Paste the data for group 2 in column B
- Enter the desired confidence level in cell O12
- The confidence interval will be given in cells Q15 and R15
Present your observations in an English sentence, relating the result to the context of the problem
We are 95% confident that the true difference in the means is between \(-0.149\) and \(0.987\) days. Note that this confidence interval contains zero, so it is plausible that there is no difference in the mean number of nights the children in the two groups participate in reading.
When defining the confidence interval in Excel, if the two groups are reversed, the means are subtracted in the opposite order. This results in a confidence interval with the opposite sign. If we assign the GEN group as the first group and the DEV group as the second, we would get a confidence interval of \((-0.987, 0.149)\).
Chronic Obstructive Pulmonary Disease (COPD)
Summarize the relevant background information
The National Heart Lung and Blood Institute gives the following explanation of COPD :
COPD, or chronic obstructive pulmonary (PULL-mun-ary) disease, is a progressive disease that makes it hard to breathe. “Progressive” means the disease gets worse over time.
COPD can cause coughing that produces large amounts of mucus (a slimy substance), wheezing, shortness of breath, chest tightness, and other symptoms.
Cigarette smoking is the leading cause of COPD. Most people who have COPD smoke or used to smoke. Long-term exposure to other lung irritants, such as air pollution, chemical fumes, or dust, also may contribute to COPD.
Describe the data collection procedures
A study was conducted in the United Kingdom to determine if there is a difference in the effectiveness of community-based rehabilitation program compared to hospital-based rehabilitation . Patients suffering from COPD were randomly assigned to either the community or hospital group. Twice a week for six weeks, they participated in two-hour educational and exercise sessions. Patients were also encouraged to exercise between sessions.
The effectiveness of the program was measured based on the total distance patients could walk at one time at a particular pace. This is called the endurance shuttle walking test (ESWT). This was measured at the beginning of the study and again at the end of the six week rehabilitation period. Data representing the improvement of the patients in each group is given in the file COPD-Rehab. The data represent the increased distance (in meters) that each patient could walk. Negative values indicate that the patient was not able to walk as far at the end of the rehabilitation treatment as at the beginning.
Because hospital-based rehabilitation tends to be more expensive, the researchers wanted to assess if there is a significant difference in the patients’ improvement under the two programs. If not, then it makes sense to refer patients to the less expensive treatment option. The purpose of this study was to determine if pulmonary rehabilitation in a community setting is as effective as rehabilitation in a hospital setting.
- Give the relevant summary statistics.
- Make an appropriate graph to illustrate the data.
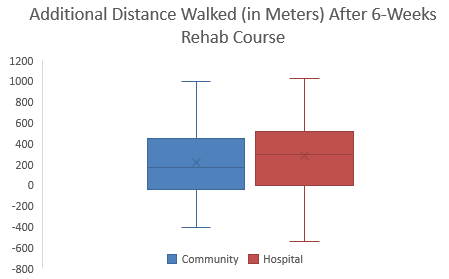
- What do you observe in the graph you made in the previous question? Does there appear to be a difference in the mean responses of the two groups?
- Verify the requirements have been met
- Find the confidence interval
- Present your observations in an English sentence, relating the result to the context of the problem
- Does there appear to be a difference in the mean improvement observed between the two groups? What does this suggest?
- Create a 90% confidence interval for the difference in the mean responses of the two groups.
- Interpret the confidence interval you computed in Question 22.
- Why is the 95% confidence interval wider than the 90% confidence interval?
Summary
In contrast to dependent samples, two samples are independent if knowing which subjects are in group 1 tells you nothing about which subjects will be in group 2. With independent samples, there is no pairing between the groups.
When conducting inference using independent samples we use \(\bar x_1\), \(s_1\), and \(n_1\) for the mean, standard deviation, and sample size, respectively, of group 1. We use the symbols \(\bar x_2\), \(s_2\), and \(n_2\) for group 2.
When working with independent samples it is important to graphically illustrate each sample separately. Combining the groups to create a single graph is not appropriate.
When conducting hypothesis tests using independent samples, the null hypothesis is always \(\mu_1=\mu_2\), indicating that there is no difference between the two populations. The alternative hypothesis can be left-tailed (\(<\)), right-tailed(\(>\)), or two-tailed(\(\ne\)).
Whenever zero is contained in the confidence interval of the difference of the true means we conclude that there is no significant difference between the two populations.
Copyright © 2020 Brigham Young University-Idaho. All rights reserved.