Lesson 10: Inference for One Mean with Sigma Known (Confidence Interval)
Optional Videos for this Lesson
Part 1
Part 2
Part 3
Part 4
Part 5
Part 6
Lesson Outcomes
By the end of this lesson, you should be able to:
- Recognize when a one mean (sigma known) confidence interval is appropriate
- Calculate the sample size required to achieve a specified margin of error and level of confidence
- Explain the meaning of a level of confidence
- Create a confidence interval for a single mean with σ known using
the following steps:
- Find the point estimate
- Calculate the margin of error for the given level of confidence
- Calculate a confidence interval from the point estimate and the margin of error
- Interpret the confidence interval
- Check the requirements for the confidence interval
- Explain how the margin of error is affected by the sample size and level of confidence
Political Polls

During an election in the United States, many polls are conducted to determine the attitudes of likely voters. Poll results are usually reported as percentages. For example, a poll might state that 49% favor the Republican candidate and 51% favor the Democratic candidate.
Polls always include a margin of error. The margin of error gives an estimate of the variability in the responses. A common value for the margin of error in political polls is 3%.
When we consider the margin of error, we estimate that the true proportion of people who favor the Republican candidate is 49% ± 3%, or in other words, between 46% and 52%. It is not obvious whether the Republican candidate is favored by more or less than 50% of the voters. In this case, the political race is too close to know who might win.
In this reading, we will explore the margin of error and its role in estimating a parameter.
Background
Point Estimators
We have learned about several statistics. Remember, a statistic is any number computed based on data. The sample statistics we have discussed are used to estimate population parameters.
|
Sample Statistic |
Population Parameter |
|
|---|---|---|
|
Mean |
\(\bar x\) |
\(\mu\) |
|
Standard Deviation |
\(s\) |
\(\sigma\) |
|
Variance |
\(s^2\) |
\(\sigma^2\) |
|
\(\vdots\) |
\(\vdots\) |
\(\vdots\) |
The statistics above are called point estimators because they are just one number (one point on a number line) that is used to estimate a parameter. Parameters are generally unknown values. Think about the mean. If \(\mu\) is unknown, how do we know if \(\bar x\) is close to it?
The short answer is that we will never know for sure if \(\bar x\) is close to \(\mu\). This does not mean that we are helpless. The laws of probability and the normal distribution provide a way for us to create a range of plausible values for a parameter (e.g. \(\mu\)) based on a statistic (e.g. \(\bar x\)).
Interval Estimators
A point estimator gives one specific value as an estimate of a parameter. An interval estimator is a range of plausible values for a parameter. We can create an interval estimate by starting with a point estimate and adding or subtracting the margin of error.
In the political poll mentioned above, the point estimate for the support of the Republican candidate is 49%. By adding and subtracting the margin of error, we get the interval estimate: 46% to 52%.
A confidence interval is a commonly used interval estimator. In this reading, we will explore how to create a confidence interval for the mean when \(\sigma\) is known.
The Margin of Error
Properties of Bell-shaped Curves
The following questions will help you review your understanding of the normal distribution.
- Fill in the blank in the following sentence.
“The 68-95-99.7% rule only applies for distributions that are _________.”
- Approximately what percentage of data from a bell-shaped distribution will lie within two standard deviations of the mean?
The Distribution of the Sample Mean
We learned in the reading Distribution of Sample Means & The Central Limit Theorem about the characteristics of the sample mean, \(\bar x\). Specifically, if the population from which the data are drawn is (i) approximately normal or (ii) if the sample size is large, then \(\bar x\) will be approximately normally distributed. Furthermore, if the original population has mean \(\mu\) and standard deviation \(\sigma\), then the sampling distribution of \(\bar x\) will have mean \(\mu\) and standard deviation \(\sigma/\sqrt{n}\).
So, if either condition (i) or (ii) is met, then we can consider the sample mean \(\bar x\) as a normal random variable with mean \(\mu\) and standard deviation \(\sigma/\sqrt{n}\). According to the 68-95-99.7% rule for symmetric bell-shaped distributions, about 95% of the time, the sample mean (\(\bar x\)) will lie within two standard deviations of the population mean (\(\mu\)).
This is an important concept. Make sure that you understand the logic above before you continue reading.
How Far is \(\bar x\) from \(\mu\), or in other words, How Far is \(\mu\) from \(\bar x\)?
Assuming that \(\bar x\) is approximately normally distributed, about 95% of the time, it will be within two standard deviations of \(\mu\).
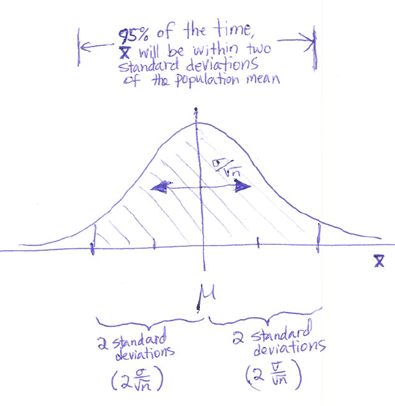
Remember, the standard deviation of \(\bar x\) is \(\frac{\sigma}{\sqrt{n}}\). For the variable \(\bar x\), two standard deviations would be equal to \(2 \frac{\sigma}{\sqrt{n}}\).
If we collect a random sample from a population and \(\bar x\) is normally distributed, then about 95% of the time the sample mean \(\bar x\) will be less than \(2 \frac{\sigma}{\sqrt{n}}\) units away from the population mean \(\mu\). Notice that this is true, whether or not we know \(\mu\).
We can express this as a probability statement:
\[ P\left( \mu - 2 \frac{\sigma}{\sqrt{n}} < \bar X < \mu + 2 \frac{\sigma}{\sqrt{n}} \right) \approx 0.95 \]
Here is the magic: If \(\bar x\) is within 2 standard deviations of \(\mu\), then \(\mu\) is within 2 standard deviations of \(\bar x\). It may seem silly to state it, but this is very important.
Click here if you love mathSo, the statement \[ P\left( \mu - 2 \frac{\sigma}{\sqrt{n}} < \bar X < \mu + 2 \frac{\sigma}{\sqrt{n}} \right) \approx 0.95 \] is equivalent to the statement \[ P\left( \bar X - 2 \frac{\sigma}{\sqrt{n}} < \mu < \bar X + 2 \frac{\sigma}{\sqrt{n}} \right) \approx 0.95 \]
Putting It All Together: Confidence Intervals for \(\mu\) when \(\sigma\) is Known
Notice that if we know \(\sigma\), then with approximately 95% confidence, \(\mu\) will be between the following two values: \[\left( \bar X - 2 \frac{\sigma}{\sqrt{n}}, ~ \bar X + 2 \frac{\sigma}{\sqrt{n}} \right)\] This equation gives a confidence interval for \(\mu\).
A confidence interval is actually a point estimate \(\left( \bar x \right)\) plus or minus the margin of error \(\left( 2 \frac{\sigma}{\sqrt{n}} \right)\).
We use the letter \(m\) to denote the margin of error: \[m = 2 \frac{\sigma}{\sqrt{n}}\] Using this definition for \(m\), our confidence interval can be written as \[( \bar x - m, ~ \bar x + m )\] or \[\bar x \pm m\] This pattern will be repeated throughout the course as we create confidence intervals of the form: \[ \left( \begin{align} point~ ~ ~ & & margin~ & & point~ ~ ~ & & margin~ \\ estimate & ~ ~- & of~error & ~ ~, & estimate & ~ ~+ & of~error \end{align} \right) \] or \[(\text{point estimate}) \pm (\text{margin of error})\]
A Little More Precision
What \(z\) Corresponds to 95% of the Area?
The 68-95-99.7% Rule for bell-shaped distribution is just a quick approximation. This is useful for estimation, but more precision is usually required.
- For a standard normal distribution, between what two \(z\)-scores will 95% of the data fall? In other words, find the values \(-z\) and \(z\) such that the area between them is equal to 0.95. Use the Normal Probability Applet.
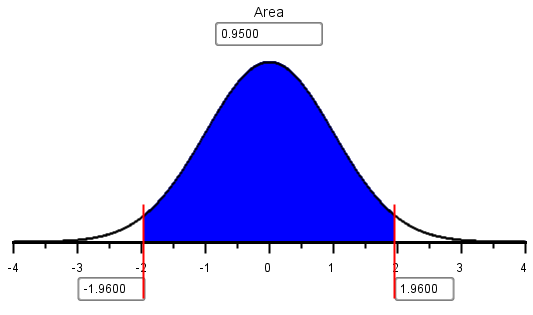
The actual formula for a 95% confidence interval for \(\mu\) (when \(\sigma\) is known) is: \[ \left( \bar x - 1.96 \frac{\sigma}{\sqrt{n}}, \bar x + 1.96 \frac{\sigma}{\sqrt{n}} \right) \] Please notice that the number 2 was used as an approximation for the actual value of 1.96. When computing a 95% confidence interval for a mean with \(\sigma\) known, please use 1.96 in the equation.
Worked Example: Rolling a Die 25 Times
We will compute a 95% confidence interval for the mean of \(n=25\) rolls of a fair die. A die was rolled 25 times. The values rolled were: \[ 3 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 4 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 6 ~ ~ ~ 5 ~ ~ ~ 6 ~ ~ ~ 3 ~ ~ ~ 4 ~ ~ ~ 2 ~ ~ ~ 2 ~ ~ ~ 5 ~ ~ ~ 6 ~ ~ ~ 2 ~ ~ ~ 6 ~ ~ ~ 4 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 5 \] The mean of these values is \(\bar x = 3.04\). It is a fact that for the outcome of a six-sided die, \(\sigma=\sqrt{\frac{35}{12}} \approx 1.7078\).
Applying the formula for a 95% confidence interval, \[ \left( \bar x - z^* \frac{\sigma}{\sqrt{n}}, ~ \bar x + z^* \frac{\sigma}{\sqrt{n}} \right) \] we get: \[ \left( 3.04 - 1.96 \frac{1.7078}{\sqrt{25}}, ~ 3.04 + 1.96 \frac{1.7078}{\sqrt{25}} \right) \] or \[ (2.37, ~ 3.71) \]
What about Other Confidence Levels?
Most of the time, researchers report 95% confidence intervals. The number 95% is called the confidence level. Sometimes it is desirable to use a level of confidence that is different than 95%. In that case, we need to use a number besides 1.96 in the calculations.
Suppose we want to create a 90% confidence interval. What value would we put in the blanks in the confidence interval formula below? \[ \left( \bar x - \underline{~ ~ ~ ? ~ ~ ~} \frac{\sigma}{\sqrt{n}}, ~ \bar x + \underline{~ ~ ~ ? ~ ~ ~} \frac{\sigma}{\sqrt{n}} \right) \] Another way to state this question is to ask, between what two \(z\)-scores will 90% of the data in a standard normal distribution fall? We need to find the values of \(-z\) and \(z\) such that the area between them is equal to 0.90. Again, we use the Normal Probability Applet.
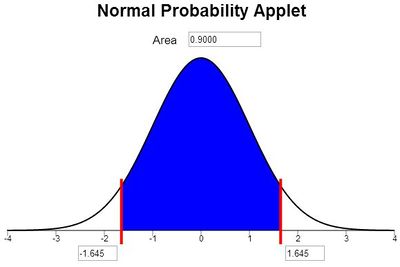
So, for a 90% confidence interval, the value of \(z*\) would be 1.645. Note: We use an asterisk (\(*\)) to indicate that \(z\) was not computed from data, but was determined based on a chosen confidence level, 90%.
The formula for a 90% confidence interval for a mean when \(\sigma\) is known is: \[ \left( \bar x - 1.645 \frac{\sigma}{\sqrt{n}}, ~ \bar x + 1.645 \frac{\sigma}{\sqrt{n}} \right) \]
When \(\sigma\) is known, we use \(z^* = 1.96\) to create 95% confidence intervals, and we use \(z^* = 1.645\) to create 90% confidence intervals.
Formula for the Confidence Interval for \(\mu\) (\(\sigma\) Known)
With this notation, the confidence interval formula generalizes to: \[ \left( \bar x - z^* \frac{\sigma}{\sqrt{n}}, ~ \bar x + z^* \frac{\sigma}{\sqrt{n}} \right) \]
where \(z^*\) is determined by the level of confidence. If you want a 90% confidence interval, then \(z^*\) is the number of standard deviations on either side of the mean that you must go to capture 90% of the data.
- If \(\bar x\) follows a normal distribution and \(\sigma\) is known, what is the equation for a 99% confidence interval for the true population mean?
- Apply the equation from the previous problem to find a 99% confidence interval for the mean value rolled on the die. Use the data given above. For convenience, they are reproduced here:
\[ 3 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 4 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 2 ~ ~ ~ 6 ~ ~ ~ 5 ~ ~ ~ 6 ~ ~ ~ 3 ~ ~ ~ 4 ~ ~ ~ 2 ~ ~ ~ 2 ~ ~ ~ 5 ~ ~ ~ 6 ~ ~ ~ 2 ~ ~ ~ 6 ~ ~ ~ 4 ~ ~ ~ 1 ~ ~ ~ 1 ~ ~ ~ 5 \]
Show/Hide Solution
The most commonly used values for \(z^*\) are:
|
Confidence |
\(z^*\) |
|---|---|
|
90% |
1.645 |
|
95% |
1.960 |
|
99% |
2.576 |
Any other values that you need can be determined using the Normal Probability Applet.
Factors Affecting the Width of the Confidence Interval
Recall that the formula to compute the confidence interval for a mean, where \(\sigma\) is known is:
\[ \left( \bar x - z^* \frac{\sigma}{\sqrt{n}}, ~ \bar x + z^* \frac{\sigma}{\sqrt{n}} \right) \]
- What would happen to the confidence interval if the sample size \(n\) was increased, but the other values were still the same?
- What would happen to the confidence interval if the confidence level were increased, say from 95% to 99%?
Interpretation of Confidence Intervals

How do we interpret confidence intervals? What do they really mean?

Consider a coin with two sides: one called “heads” and the other called “tails”. Imagine that you flipped this coin, but you have not looked at it yet. What is the probability that the coin shows heads?
Strangely enough, the answer is, it depends! If the head is facing up, then the probability that the coin shows heads is 1. If the head is facing down, then the probability that it shows heads is 0.
The coin has been tossed. There is no randomness left in the process. So, either the head is facing up or it is facing down. So, the probability that the coin shows heads is either 1 or 0. (We just don’t know which.) The fact that we do not know the outcome does not change it or make it random.
Before we toss the coin, the probability that the coin will show heads is \(\frac{1}{2}=0.5\). After we toss the coin, the probability that we get heads is 1 or 0.
Transferring this reasoning to confidence intervals, we get a similar result.
Once we have collected data on something, there is no randomness in the system. Any confidence interval that is created using that data will either contain the true parameter (\(\mu\)) or it will not. After collecting data, the probability that a specific confidence interval will contain \(\mu\) is either 1 or 0.
Consider the 95% confidence interval for the true mean of 25 rolls of
a fair die. We found the 95% confidence interval to be: \((2.37, 3.71)\).
When we interpret this confidence interval, we say, “We are 95%
confident that the true mean is between 2.37 and 3.71.”
The word, “confident” implies that if we repeated this process many, many times, 95% of the confidence intervals we would get would contain the true mean \(\mu\). It does not imply anything about whether or not one specific confidence interval will contain the true mean.
We do not say that “there is a 95% probability (or chance) that the true mean is between 2.37 and 3.71.” The probability that the true mean \(\mu\) is between 2.37 and 3.71 is either 1 or 0.
Requirements
There are three requirements that need to be checked when computing a confidence interval for a mean with \(\sigma\) known:
- A simple random sample was drawn from the population
- \(\bar x\) is normally distributed
- \(\sigma\) is assumed to be known
The requirement of normality is satisfied if (a) the raw data are normally distributed or (b) the sample size is large. This procedure is robust to moderate departures from normality. Even if the requirement that \(\bar x\) is normally distributed is not satisfied perfectly, it is usually okay to conduct the test.
In practice, we never really know \(\sigma\). This procedure is primarily used to help you understand the idea of confidence intervals. When \(\sigma\) is unknown, we use a slightly different computation.
Example: Costs of CABG Surgery
This reading focuses on an important aspect of designing a study: determining the sample size.

It is important for health care administrators to know the mean hospital costs for patients who have coronary artery bypass graft (CABG) surgery. A large hospital is planning a study to determine their mean costs for patients who have CABG surgery.
A study will be conducted in which the charts of patients who had CABG surgery will be sampled, and their hospital costs will be recorded. For budgetary reasons, the hospital administrators do not want to collect a sample that is too large. However, if the sample size is not large enough, the confidence interval will be too wide to be useful as a planning tool.
After a discussion among the senior administration, they have determined that they want to estimate the mean hospital costs of CABG surgery within $2000 (i.e., plus or minus $2000.) In other words, they want the confidence interval for the true mean to have a margin of error of $2000 dollars.
Recall the equation for the confidence interval is: \[ \left( \bar x - z^* \frac{\sigma}{\sqrt{n}}, \bar x + z^* \frac{\sigma}{\sqrt{n}} \right) \] The part of the equation that is added to and subtracted from \(\bar x\) is called the margin of error. We will denote the margin of error by the letter \(m\). \[ m=z^* \frac{\sigma}{\sqrt{n}} \] To use this formula, the parameter \(\sigma\) must be given to us. It is the true standard deviation of the data you are observing. If you do not know \(\sigma\), you can estimate it using the standard deviation reported in a previous study or by conducting a pilot study. A study published by another hospital reported that the standard deviation of the costs for CABG surgery was $28,705.
In the following questions, you will compute the margin of error, \(m\), for a future study of the hospital costs for CABG surgery. The hospital administrators want to use a 95% level of confidence. Assume the standard deviation can be estimated to be \(\sigma = \$28,705\).
- If the hospital administrators want to be 95% confident in the results, what should the value of \(z^*\) be?
- If the hospital collects a sample of \(n=100\) patients’ costs, what would the margin of error be?
- If the hospital collects a sample of \(n=1000\) patients’ costs, what would the margin of error be?
- Choose any other value for the sample size, \(n\). Find the margin of error for your sample size.
- Repeat Question 11 until you find the sample size that will yield a margin of error as close to $2000 as possible, without going over.
Sample Size Calculations
The process you followed in Questions 8 - 12 is effective, but tedious. There must be an easier way! The trick is to solve the margin of error equation \(m = z^* \frac{\sigma}{\sqrt{n}}\) for \(n\).
Click here if you love mathThis gives us the sample size formula, which tells the number of observations required in order to obtain a specified margin of error: \[ n = \left( \frac{z^*\sigma}{m} \right)^2 \]
Once the level of confidence is selected, \(z^*\) is automatically determined. In practice, the most common level of confidence is 95%, which means that \(z^*\) would equal 1.96.
- In Question 12, you used the process of guess-and-check to find the sample size. For this question, use the sample size formula to compute the sample size required to estimate the mean cost of CABG surgery, \(\mu\), within $2000 with 95% confidence. Recall that in a previous study, the standard deviation was found to be \(\sigma = \$28,705\).
Rounding Up
In Question 13, you computed the sample size required to get a margin of error of $2000. Notice that the result was 791.3, which is not a whole number. What does that mean? Does that suggest that you will survey only a fraction of the last patient’s costs? Of course not!
When doing sample size calculations, if the answer is not a whole number, you always round up to the next highest whole number. This will allow you to get a sample size that is large enough to attain your desired margin of error. If you want to estimate the mean cost of CABG surgery within $2000 with 95% confidence, you will need to survey the files of 792 patients.
- Answer this question without doing any computations. If the hospital administrators wanted to estimate the mean cost of CABG surgery with a margin of error of $1000 at the 95% confidence level, should the sample size be larger or smaller than \(n=792\)?
- Find the sample size required to estimate the mean cost of CABG surgery with a margin of error of $1000 and with a 95% confidence level.
- What happened to the sample size required when the margin of error is cut in half from $2000 to $1000?
- Remember the sample size required to have a margin of error of $2000 at the 95% level of confidence is \(n=792\). If we wanted to estimate the mean cost with the same margin of error at the 99% level of confidence, would the sample size be larger or smaller?
- Find the sample size required to estimate the mean cost of CABG surgery with a margin of error of $2000 and at the 99% confidence level.
- If we increase the confidence level, what happens to the required sample size?
Example: Grade Inflation
The administration at BYU-Idaho is concerned about the possibility of grade inflation in their courses. Grades in a course are coded on a scale from 0 to 4, as given in the following table:
| A | A- | B+ | B | B- | C+ | C | C- | D+ | D | D- | F |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 3.7 | 3.3 | 3 | 2.7 | 2.3 | 2 | 1.7 | 1.3 | 1 | 0.7 | 0 |
Historical records indicate that the standard deviation of the numerical value for the grades students’ receive in a course is \(\sigma = 0.68\).
Due to the confidential nature of grades, the administration will not release the current value of the mean grade earned on campus. An old reference indicates that the true mean value of the grades earned at BYU-Idaho students is 3.15. It would be interesting to estimate the current mean grade point average at BYU-Idaho.
You have been asked to help study the issue of grade inflation at BYU-Idaho. A certain number of individual grades will need to be sampled to estimate the mean grade earned at BYU-Idaho.
- What sample size would be required to estimate the true mean grade earned at BYU-Idaho with 95% confidence and a margin of error of 0.2 grade points?
- What sample size would be required to estimate the true mean grade earned at BYU-Idaho with 98% confidence and a margin of error of 0.2 grade points?
- What sample size would be required to estimate the true mean grade earned at BYU-Idaho with 95% confidence and a margin of error of 0.1 grade points?
- What sample size would be required to estimate the true mean grade earned at BYU-Idaho with 98% confidence and a margin of error of 0.1 grade points?
Summary
The margin of error gives an estimate of the variability of responses. It is calculated as \(\displaystyle{m=z^*\frac{\sigma}{\sqrt{n}}}\) where \(z^*\) represents a calculated z-score corresponding to a particular confidence level.
A confidence interval is an interval estimator used to give a range of plausible values for a parameter. The width of a confidence interval depends on the chosen confidence level (and its corresponding value of \(z^*\)) as well as the sample size (\(n\)). This is the equation for calculating confidence intervals: \[\displaystyle{\left(\bar x-z^*\frac{\sigma}{\sqrt{n}},~\bar x+z^*\frac{\sigma}{\sqrt{n}}\right)}\]
The sample size formula allows us to estimate the number of observations required to obtain a specific margin of error. \(\displaystyle{n=\left(\frac{z^*\sigma}{m}\right)^2}\)
Copyright © 2020 Brigham Young University-Idaho. All rights reserved.
Comments
What confidence level should be used? The most common choice for the confidence level is 95%. Other values are occasionally used, but this tends to meet the needs of most researchers.
How do we find the value of \(\sigma\)? In a statistics class, this number will be given to you in the problem. In real life, you will need to estimate this value based on either (\(i\)) a previous study, (\(ii\)) the results of a pilot study, or (\(iii\)) your best professional judgement (an educated guess). Sometimes it is not possible to use data from a previous study or to easily conduct a pilot study. In these cases, the only thing a researcher can do is to use their understanding of the process to make a good guess of the value of \(\sigma\). Ultimately, sample size calculations are nothing more than a good estimate of the actual sample size that will be required.
In many cases, budgets will limit the sample size that can be drawn. A researcher must assess whether a smaller-than-ideal sample will suffice for their needs. This is one of the difficult issues that arises in the actual practice of statistics.