Blocking Introduction
Introduction
In the chapter that describes BF[1], a very simple example was used to assign 3 treatments to 6 subjects completely at random. In that example, treatment C was assigned to the last experimental runs (order number 5 and 6). In some experiments, we would not expect order to matter much and this would not concern us. But in other experiments, if we thought order could affect the response, we may be confounding treatment C with the fact that it was only applied in the last two experimental runs.
| Subject | Treatment | Order |
|---|---|---|
| Subject 1 | A | 4 |
| Subject 2 | B | 3 |
| Subject 3 | C | 6 |
| Subject 4 | C | 5 |
| Subject 5 | A | 1 |
| Subject 6 | B | 2 |
For example, the experimental units may change (melt, or become more brittle) as it waits its turn to receive a treatment. Or, in an experiment that requires the reuse of tools (such as a cutting tool, or measurement tool) to do the experiment, the calibration or sharpness of the tool may change gradually with each run of the experiment. If people are somehow involved in the administration of the experiment, fatigue or learning may slightly change the way in which the experiment is conducted. In any of these examples, a difference in the response may be due to the order of the experimental run rather than the treatment itself.
To prevent confounding due to an “unlucky” treatment randomization, we can implement a more strategic approach to random assignment. Since there are 3 treatments and 6 experimental runs, we can break the 6 experimental runs into two groups, called blocks. Each block will have 3 experimental runs: one for each treatment. Assignment of treatment to experimental run will be done completely at random within each block. In this way, it is like conducting 2 mini-experiments and each treatment is guaranteed to be represented in each phase of the data collection: once in the first 3 runs, and once in the second three runs.
In this example order was identified as a source of variation in the response. We are not interested in the effect of order, but wanted to ensure it did not cause confounding with the treatment effect. This type of factor can be called a nuisance factor. Levels of a nuisance factors are often used as blocks.
In addition to order in which treatments are applied, the experimental unit itself represents a nuisance source of variation we need to deal with. For example, when studying a new method of teaching, the IQ of the student (i.e. experimental unit) could be considered a nuisance factor. We could assign treatment to students completely at random. But what would happen if, simply by random chance, all the people with low IQ’s were assigned to the control group, and all people with high IQ’s were assigned to receive the new teaching method? The effect of the teaching method would be confounded with the effect of the students’ high IQ.
Another common nuisance factor used for blocking is a characteristic of the environment in which the experiment is conducted. For example, researchers desire to study the yield of different types of seeds. The larger field may be divided into smaller subplots. Each subplot is assigned one of the different seeds under development. Each plant in the subplot is then measured. The location of the subplot in which the seeds are planted may be a nuisance factor. Nuisance factors are often general factors that are easily identified, but are actually proxies for other more complex factors that we don’t both to identify or measure. In this case, subplot is a nuisance factor that really represents a lot of other things: soil chemistry, sun exposure, water received, etc.
Blocking as an Alternative to Assignment Completely at Random
Up to this point, randomization has been our primary tool for dealing with these nuisance factors. In the factorial designs we have assigned treatments to experimental units completely at random: each experimental received exactly one treatment. However, as we have seen, making assignments completely at random may lead to “unlucky” scenarios that create confounding or bias.
Furthermore, in some cases, it may not be practical or possible to completely randomize the nuisance factor.
Last but not least, in a completely randomized design, variation from the uncontrolled and unmeasured nuisance factor is lumped in with the unexplained variation, thereby increasing variance of the residual errors and making it more difficult to find statistical significance.
Instead of treating the nuisance factor as something not controlled and not measured, with blocking the nuisance factor is incorporated into the design and becomes a factor that is measured during the experiment. Thus, variation in the response due to the nuisance factor is converted from unexplained variance to explained variance. In other words, the mean squared error will decrease. The F statistic for testing significance of treatment effects will increase since it represents the ratio of mean squares for treatments (which remains unchanged) to mean squares for error (which is smaller due to blocking).
How to Create Blocks
To create blocks, you must put your experimental units into groups. The size of each group should be equal to the number of treatment factor levels. These groups are called blocks. For blocking to be effective at reducing error variance:
- experimental units within each block should be similar in terms of their anticipated value on the response variable ,
- the blocking variable should be correlated with the response,
- each block will be different from the other blocks (in terms of the response variable).
Inside each block, treatments are assigned completely at random to experimental units.
There are 3 ways to create blocks. An example of each of these techniques is provided below.
Sort experimental units according to their values on the nuisance variable
Subdivide experimental material into smaller sections to be used as experimental units
Reuse experimental units, so that each experimental unit is exposed to each treatment.
Block by Sorting
We return to the above example regarding a study aimed at measuring the effect of a new teaching method. In the section above, we already exposed the potential risks of assigning treatments to people completely at random because differences in starting IQ could get in the way of detecting the true effect of the new teaching method.
To block by sorting we would sort the study participants according to their IQ. The treatment factor has two levels: a control group and the new teaching method. Therefore, each block will have just 2 individuals. The people with the top two IQ’s would form the first block, the next two highest IQ individuals would form the second block, and so on until the 2 people with the lowest IQ’s form the last block. Inside each of those blocks, one person will be randomly assigned to receive the control and the other person will receive the new teaching method. This study is blocked on IQ.
Figure 1 shows the process of assigning treatments to blocks created by sorting.
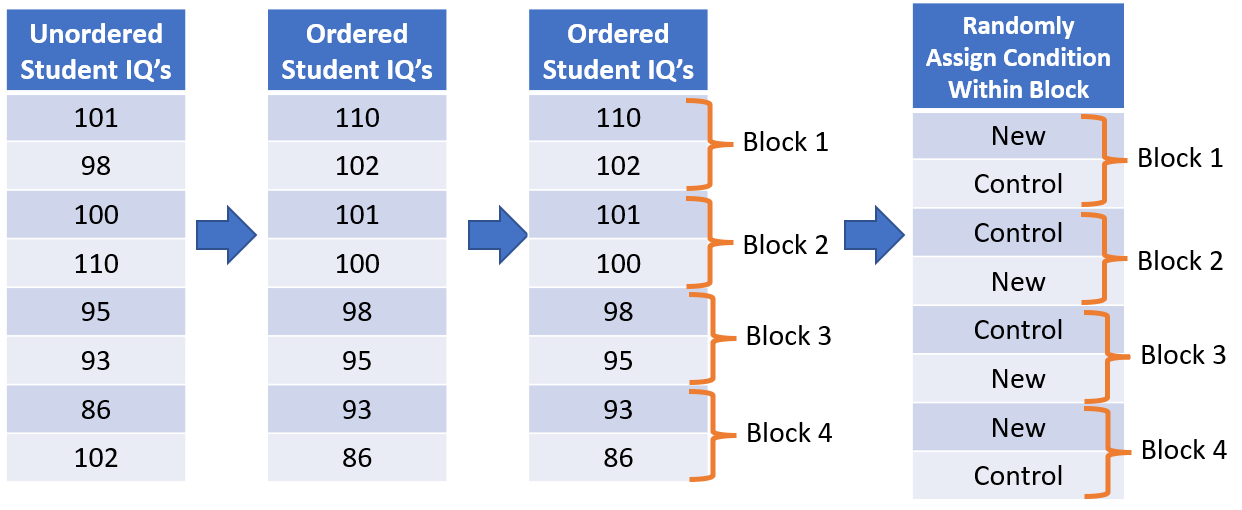
This is also the technique that was used to address the concern about run order in the example at the top of the page. We sorted and grouped the units based on run order.
Block by Subdividing the Experimental Material into Smaller Sections
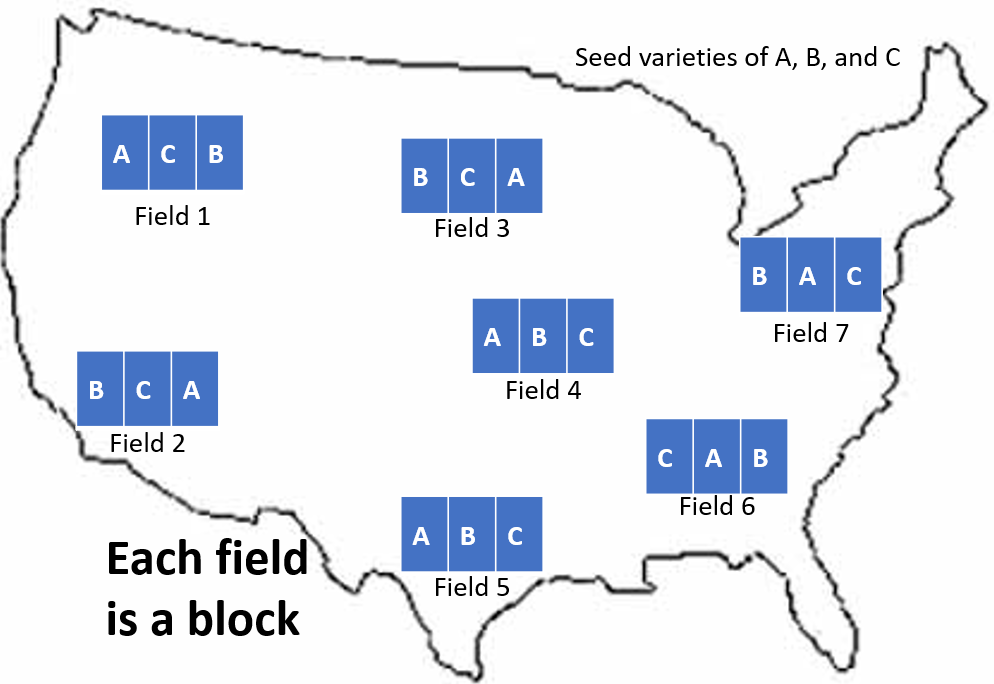
A seed company is experimenting with developing seeds for a new variety of cabbage. Specifically, 3 different seeds have made it to this final stage of testing. The company has fields in multiple states in the United States. They use these fields to test out their new seeds. Though researchers try to treat each field similarly, each field is different in terms of elevation, rain fall, soil chemistry, etc. To address these differences, the researchers decided to treat each field as a block. Each field is divided into 3 subplots. Then each variety of seed is randomly assigned to a subplot in that field. In this way, the researchers have blocked on field; the effect of field is measured and accounted for.
Figure 21 illustrates this seed example.
Block by Reusing Experimental Units
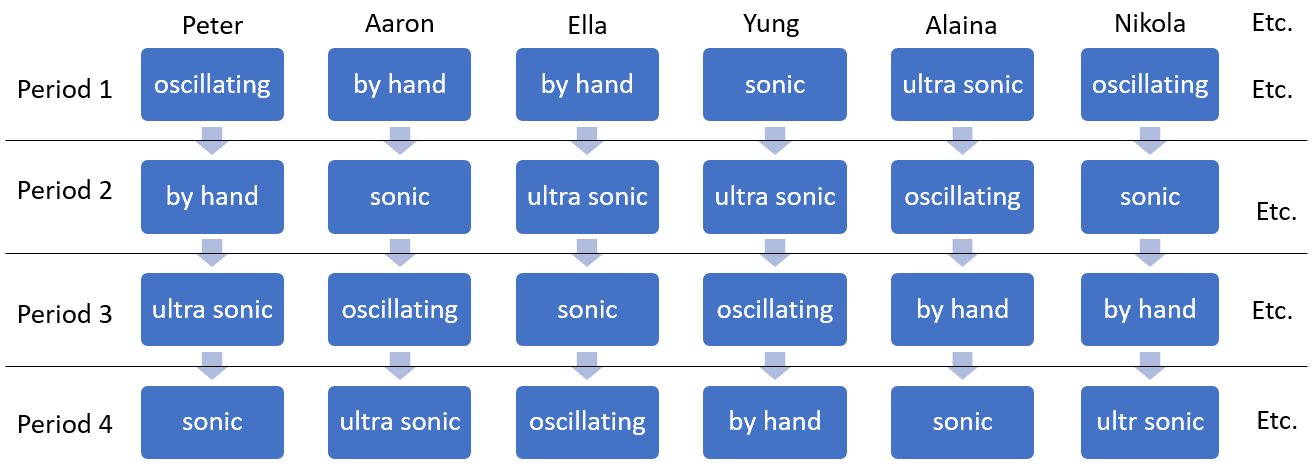
Our toothbrush example can be tweaked to use blocking. In the basic factorial examples, each person received one treatment. If researchers were concerned that a person’s style and quality of brushing may have a substantial impact on the results of the study, this could be addressed by ensuring that each person tried each brush. The experiment could be set up such that a person uses a particular brush for a set period. Their plaque amount would be measured, their teeth cleaned, and then they would use a different brush for the same set amount of time. The process would repeat until the person had used all 4 brushes. For each person, the order of the brushes would be determined randomly (see Figure 3). In this example, the researchers have blocked on person.
Some Specific Designs that Use Blocking
There are infinite variations and combinations of designs to consider that use blocks. We just cover a few of the basics as mentioned below.
The simplest method is a complete block design, or CB[1]. In this design, there is just one blocking factor and one treatment factor. It is called a complete block because all the treatments are represented in each block. Incomplete block designs, where each block does not have all the treatments represented, are not treated in this book.
What should you do if there are two blocking variables? In the special case when the two blocking factors have the same number of levels, then a Latin Square (LS) design can be used. There are many other scenarios and set-ups that use two (or more) block variables that are not explicitly addressed in this book.
Another common and very powerful design is a split-plot/repeated measures design. A split plot/repeated measures design is like a complete block CB[1], except that there is an additional treatment factor. A level of this additional treatment factor is randomly assigned to each block. This design incorporates another concept called “nesting”.
Analysis of covariance (ANCOVA)is another technique that will be covered in this book. It is not considered blocking, but it is also a technique for dealing with nuisance sources of variation.
Footnotes
Outline of the United States, by unknown author, is licensed under CC-BY-NC-ND↩︎