By the way, contrary to what the article suggests, I don’t believe saving your workspace is a good idea unless you think you’ll need it. It just slows down your computer. That’s the point of a script or markdown file, all the code is already saved so you can reproduce the workspace if necessary.
“To pivot or not to pivot?”, that is the question. When do we need to pivot our data, and when can we leave it as is? Wider formats are often easier for humans to read and parse in a large grid/table. However, the tidyverse generally assumes your data is presented in a longer format. If our data has been stored in a wide format, we’ll have to first pivot longer before we can do anything with the data. On the other hand, we may have to pivot wider to create a table of the data that’s easier for humans to process.
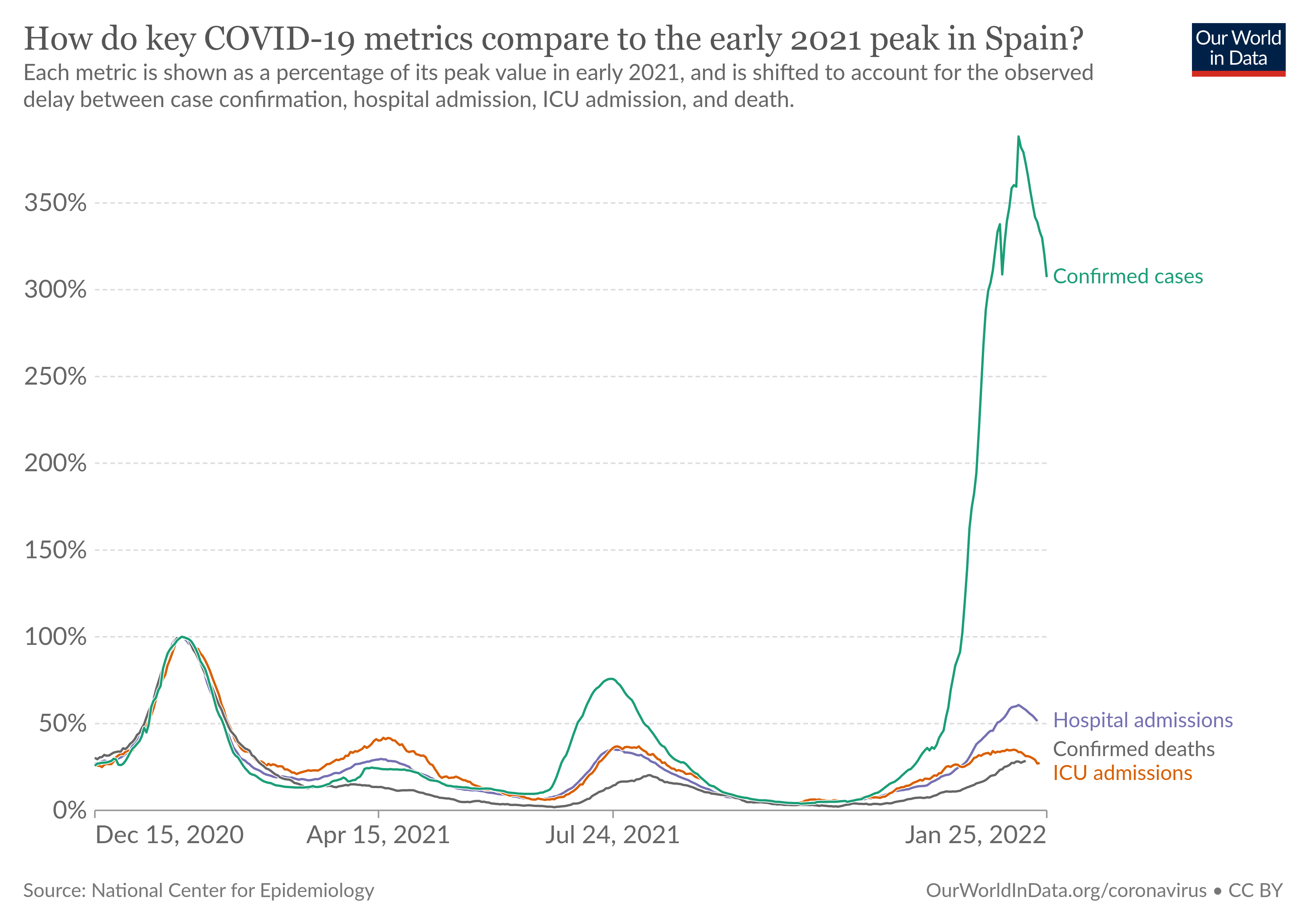
Consider the following data, with an accompanying chart.
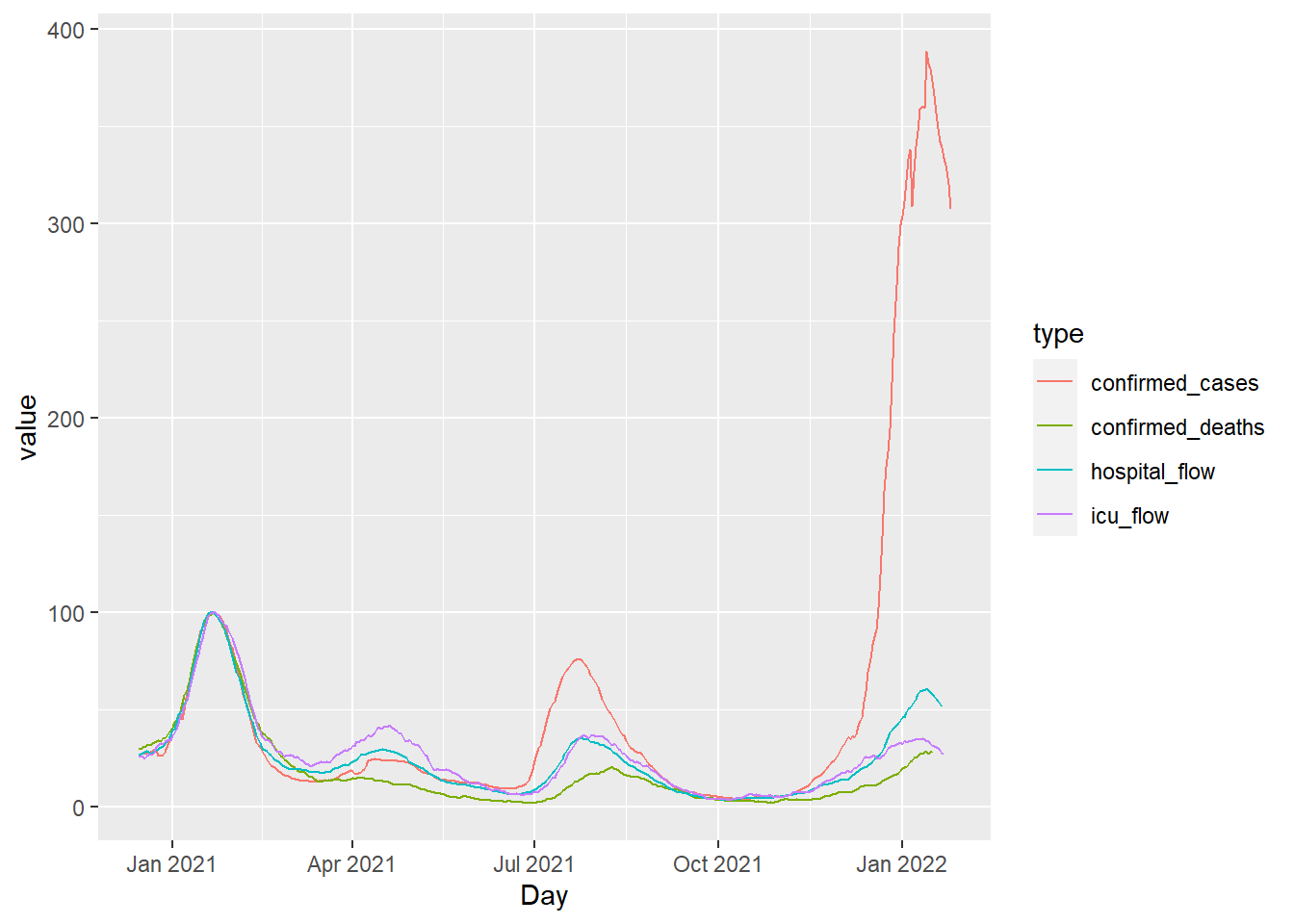
The following code uses pivot_longer to appropriately wrangle the last 4 columns of the data set into two columns (type and value), and then constructs a bare bones (ignoring theme elements) plot to visualize the data.
Warning: Removed 16 rows containing missing values or values outside the scale range
(`geom_line()`).
This rough visualization can certainly be improved, but the wrangling phase and basic plot creation is complete. Our goal in this task is to practice this process several times, on various data sets, asking each time if pivoting is needed and then creating the bare bones replica of the graph.
There are 6 visualizations below, each with a link to their accompanying data and the source location on OurWorldInData. Appropriately wrangle the data to create a rough visualization. Some will need a pivot_longer() command, while others won’t. Once you have made each basic visualization, add in theme elements (title, labels, caption, axes, annotations, etc.) that you have struggle with before. If you’re already a pro at adding titles, then skip it and focus on something you can improve.
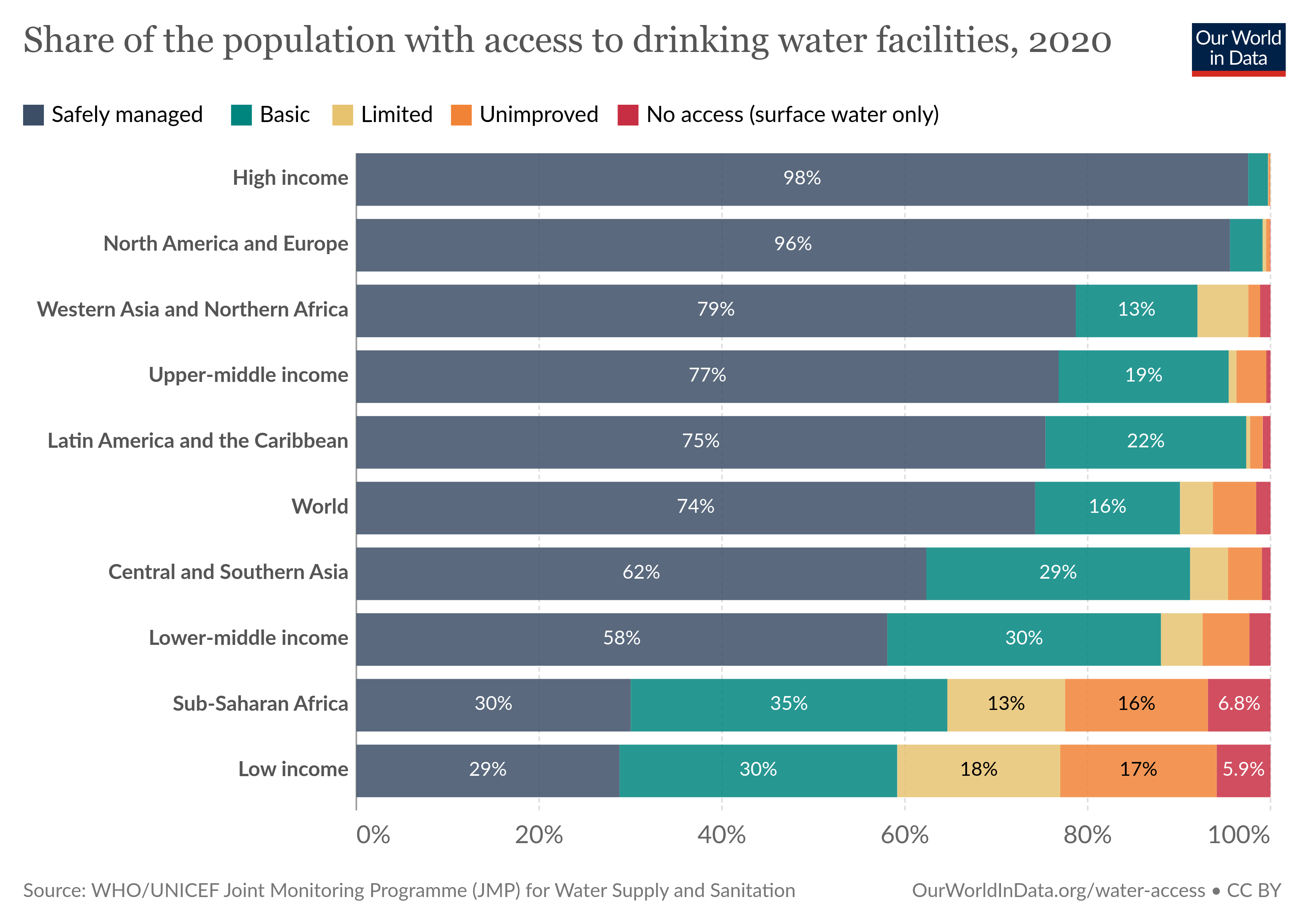
https://byuistats.github.io/DS350_2022/files/to-pivot-or-not/access-drinking-water-stacked.csv (Source. Make sure you look up the difference between geom_bar and geom_col. Feel free to pick 4 groups, instead of all 10, when you filter. It’s OK if your initial rough visualization doesn’t have the bars in the correct order.)
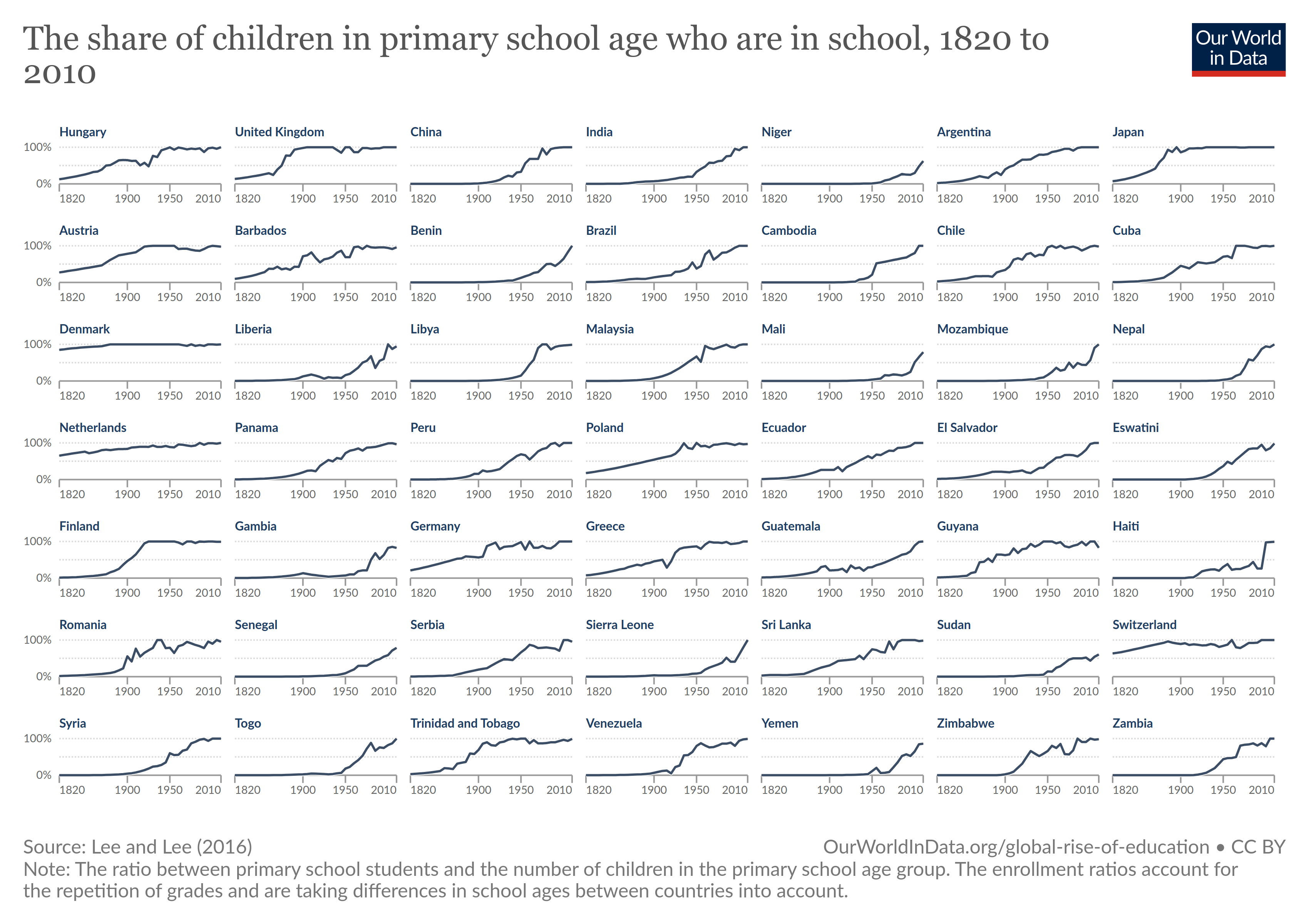
https://byuistats.github.io/DS350_2022/files/to-pivot-or-not/primary-enrollment-selected-countries.csv (Source. Feel free to filter to include 4 countries, rather than 49, and get them in a 2 by 2 grid.)
Render the .qmd. Push the .qmd, .md, and .html files to your GitHub repository.
Submit
In I-learn submit a link to the .md file on GitHub.