5 Functions and Spacial Data
The tasks in this unit will help prepare you to do the following:
- These will be updated soon.
The case studies, which appears at the end of this unit, give you an opportunity to demonstrate mastery of the objectives above.
5.1 Task: Functions Reading
- Read R4DS: Functions. As you read, do at least two of the practice exercises from each section. Get as far as you can in one hour. You are welcome to perform your computations in a script (.R) or markdown (.Rmd) file.
- If you would like some interactive practice, please use these interactive primers located on rstudio.cloud.
- When you are done, push your work to your GitHub repo. Then pick at least two exercises you would like to discuss (perhaps ones that were very helpful, or very difficult). Be prepared to share them with your team.
5.2 Task: Chipotle Promo - Part 1
You got your dream job working as a data analyst for one of your favorite restaurants, Chipotle. Chipotle is planning to run a large 1 or 2 day promotion. They would like the promotion to take place when the restaurant is busiest. They have gathered restaurant level data that you can use to answer the question, “What is the busiest day in the restaurant?”
We will answer this question over the course of a couple of tasks. In this task, we’ll focus on creating some functions that we’ll iterate over in a later task.
-
Before exploring the Chipotle data, let’s walk through the process of creating new functions in a different context we’ve seen before. We previous explored the
stri_stats_latex()function from thestringipackage. Run the code below to load the needed libraries and remind yourself whatstri_stats_latex()does.library(tidyverse) library(stringi) sentences[1] stri_stats_latex(sentences[1])Rather than get a list of facts about a string, we can create our own functions to extract exactly the pieces of information we want, such as the word count or number of white space characters. Below we create functions to individually count 4 specific things.
count_words <- function(x){stri_stats_latex(x)["Words"]} count_chars_word <- function(x){stri_stats_latex(x)["CharsWord"]} count_chars_white <- function(x){stri_stats_latex(x)["CharsWhite"]} count_len <- function(x){str_length(x)} sentences[1] count_words(sentences[1]) count_chars_word(sentences[1]) count_chars_white(sentences[1]) count_len(sentences[1])We can count all 4 items above and return the information in a nice tibble (tidy table), by writing other functions, as shown below.
count_stats_wide <- function(x){ tibble( words = count_words(x), chars_word = count_chars_word(x), chars_white = count_chars_white(x), len = count_len(x) ) } count_stats_long <- function(x){ tibble( name = c("words","chars_word","chars_white","len"), value = c(count_words(x), count_chars_word(x), count_chars_white(x), count_len(x)) ) } sentences[1] count_stats_wide(sentences[1]) count_stats_long(sentences[1])Run all the code above, and come with any questions you have about parts of the code. We’re now ready to tackle the Chipotle data.
-
Read in the restaurant level data from
https://byuistats.github.io/M335/data/chipotle_reduced.csv.chp <- read_csv("https://byuistats.github.io/M335/data/chipotle_reduced.csv")- This data dictionary can help answer questions you may have about the data.
-
The data contains a column
popularity_by_day. This column contains a lot of information we need to extract from a string. As an example, for the restaurant withplacekeyequal to “zzw-222@5vg-nwf-mp9”, we can obtain atest_stringbelow.#"{\"Monday\":94,\"Tuesday\":76,\"Wednesday\":89,\"Thursday\":106,\"Friday\":130,\"Saturday\":128,\"Sunday\":58}" #This code uses base R to extract the string. test_string <- chp$popularity_by_day[chp$placekey == "zzw-222@5vg-nwf-mp9"] #This code uses dplyr to extract the string test_string <- chp %>% filter(placekey == "zzw-222@5vg-nwf-mp9") %>% pull(popularity_by_day) test_stringYour task is to create 2 functions to help us obtain meaningful data from these strings.
The first function should take as input a string from the
popularity_by_daycolumn, such astest_stringabove, and return a tibble that contains the name of each day of the week in one column, and the number of visits at that store in the other column.The second function should have the same input as the previous function (so a long string from the
popularity_by_daycolumn), and return the most popular day of the week, in terms of visists (or a comma separated string if there are ties).
-
Verify that your functions are working.
- For the
test_stringabove (with placekey “zzw-222@5vg-nwf-mp9”), your first function should return a table similar to the one below, while the second function should return “Friday”.
# Monday 94 # Tuesday 76 # Wednesday 89 # Thursday 106 # Friday 130 # Saturday 128 # Sunday 58- For the
popularity_by_daystring corresponding to placekey “22c-222@5z5-3rs-hwk”, your first function should return a table similar to the one below, while the second function should return “Saturday”.
# Monday 18 # Tuesday 16 # Wednesday 14 # Thursday 27 # Friday 26 # Saturday 36 # Sunday 20- For the
popularity_by_daystring corresponding to placekey “zzw-223@5r8-fqv-xkf”, your first function should return a table similar to the one below, while the second function should return “Wednesday, Saturday”.
# Monday 0 # Tuesday 0 # Wednesday 1 # Thursday 0 # Friday 0 # Saturday 1 # Sunday 0 - For the
5.3 Task: Iteration Reading
- Read R4DS: Iteration. If you are already familiar with for loops, then skim read those sections and move on as quickly as possible to section 21.5 on the
map_*functions. As you read, do at least two of the practice exercises from each section. Get as far as you can in one hour. You are welcome to perform your computations in a script (.R) or markdown (.Rmd) file. - If you would like some interactive practice, please use these interactive primers located on rstudio.cloud.
- When you are done, push your work to your GitHub repo. Then pick at least two exercises you would like to discuss (perhaps ones that were very helpful, or very difficult). Be prepared to share them with your team.
5.4 Task: Chipotle Promo - Part 2
You got your dream job working as a data analyst for one of your favorite restaurants, Chipotle. Chipotle is planning to run a large 1 or 2 day promotion. They would like the promotion to take place when the restaurant is busiest. They have gathered restaurant level data that you can use to answer the question, “What is the busiest day in the restaurant?”
We will answer this question over the course of a couple of assignments. In this task, we’ll use the functions from the previous task to answer the question.
-
Before exploring the Chipotle data, let’s walk through the process of iterating over the functions, related to counting information about sentences, that we created in the previous task. Run the code below to load the libraries and functions, and remind yourself what each function does.
library(tidyverse) library(stringi) count_words <- function(x){stri_stats_latex(x)["Words"]} count_chars_word <- function(x){stri_stats_latex(x)["CharsWord"]} count_chars_white <- function(x){stri_stats_latex(x)["CharsWhite"]} count_len <- function(x){str_length(x)} count_stats_long <- function(x){ tibble( name = c("words","chars_word","chars_white","len"), value = c(count_words(x), count_chars_word(x), count_chars_white(x), count_len(x)) ) } sentences[1] count_stats_long(sentences[1])Let’s now examine more than one sentence. There are 720 total sentences, but we will just explore the first 3 to start with. The code below places the first three sentences into a tibble, and then uses the
map_intcommand to iteratively apply thecount_wordsfunction to each sentence, using mutate to store the results in a new column of our tibble.(my_sentences <- tibble(sentence = sentences[1:3])) my_sentences %>% mutate(words = map_int(sentence,count_words))We used
map_intabove because we knew that the output ofcount_wordswould be an integer for each sentence. The functioncount_stats_longoutputs a tibble, rather than a vector. Usingmap()will return a list of tibbles, which we can then store in a column of our tibble (so tibbles inside of a tibble). We call this “nested” data, and can use theunnest()function to expand each tibble. Run the code below to see howmap()andunnest()work together.#Without using unnest(), you can see the nested tibble. my_sentences %>% mutate(stuff = map(sentence,count_stats_long)) #Using unnest() will expand the tibble in place. my_sentences %>% mutate(stuff = map(sentence,count_stats_long)) %>% unnest(cols = c(stuff))You may have noticed in the examples above that the number of words was equal to the number of white space characters for the first 3 sentences. Does this trend continue if we look at all 720 sentences in the
sentencesvectors? One way to examine this is to compare the distributions of each of our 4 variables by constructing side-by-side boxplots. When the data is in long format, it makes it easy to compare the distributions of the 4 different statistics. Run the code below to make the comparison.my_stats_long <- tibble(sentence = sentences) %>% mutate(stuff = map(sentence,count_stats_long)) %>% unnest(cols = c(stuff)) my_stats_long %>% filter(name %in% c("words","chars_white")) %>% ggplot(aes(x = name, y = value)) + geom_boxplot()The distributions are very similar, but there is at least one difference. What do you think causes the difference between
wordsandchars_white? We could explore this more, but let’s move on to the Chipotle data. Let’s now return to the Chipotle data. Use the second function you created in the previous task, the function that outputted the most popular day of the week, to tally across the restaurants how often each day of the week is selected as the most popular day. (Which
map_*()function will you need to use?) Then visualize the results.Now use the first function you created in the previous task, the one that outputted a tibble, to combine the
popularity_by_daydata across all the restaurants. (You’ll can usemap()andunnest()). Then visualize the frequency distribution of visits by day of the week regardless of restaurant.Pick one (or both) of your charts above and facet by region.
Based on your above visualizations, make a recommendation regarding which day(s) of the week Chipotle’s big promotion should run.
5.5 Task: Begin Case Study 7
Each case study throughout the semester will ask you to demonstrate what you’ve learned in the context of an open ended case study. The individual prep activity will always include a “being” reading which will lead to an in class discussion.
Complete the Being Reading section of Case Study 7. This will require that you read an article(s), and come to class with two or three things to share.
Download the data for the case study and begin exploring it. Your goal at this point is to simply to understand the data better. As needed, make charts and or summary tables to help you explore the data. Be prepared to share any questions you have about the data with your team.
Identify what visualizations this case study wants you to create. For each visualization, construct a paper sketch, listing the aesthetics (x, y, color, group, label, etc.), the geometries, any faceting, etc., that you want to appear in your visualization. Then construct on paper an outline of the table of data that you’ll need to create said visualization. You do not need to actually perform any computations in R, rather create rough hand sketches of the visualization and table that you can share with your team in class.
With any remaining time, feel free to start transferring your plans into code, and perform the wrangling and visualizing with R.
5.6 Task: Spatial Data Reading
Up to this point, we have dealt with data that fits into the tidy format without much effort. Spatial data has many complicating factors that have made handling spatial data in R complicated. Big strides are being made to make spatial data tidy in R. However; we are in the middle of the transition. We will focus our efforts today on using library(sf) and library(USAboundaries).
-
Install both the
sfandUSAboundariespackages.Check the sf Package GitHub page for platform specific instructions on how to install
sf. Based on your platform, you may need to install some other things first.Check the USA Boundaries Package GitHub page for instructions on how to install
USAboundaries. Installing the development version seems to avoid the most common issues.
-
Run each line, one by one, of the following code. Form questions about any lines that don’t make sense, and ask them in Slack.
library(tidyverse) library(sf) library(USAboundaries) # Let's plot a map of North Carolina, using base R and ggplot nc <- read_sf(system.file("shape/nc.shp", package = "sf")) plot(nc) ggplot() + geom_sf(data = nc) # What is the "nc" object? glimpse(nc) # What is the geometry column? plot(nc$geometry) plot(nc$geometry[[1]]) # We can use the other columns as aesthetics in ggplot ggplot() + geom_sf(aes(fill = AREA), data = nc, colour = "white") # Maps can come from all kinds of places. The class function states object's type. # Let's map New Zealand using the maps package. nz_map <- maps::map("nz", plot = FALSE) class(nz_map) class(nc) plot(nz_map) #We can convert types to sf using st_as_sf nz_sf <- st_as_sf(nz_map) class(nz_sf) plot(nz_sf) ggplot() + geom_sf(data = nz_sf) # From USAboundaries package, we get lots more info. # Getting errors? Please install the development branch. # https://stackoverflow.com/questions/62438256/using-usaboundaries # devtools::install_github("ropensci/USAboundariesData") state_data <- us_states() ggplot() + geom_sf(data = state_data) county_data <- us_counties() ggplot() + geom_sf(data = county_data) # And we can combine two plots (USA with NZ) as we expect. ggplot() + geom_sf(data = state_data) + geom_sf(data = nz_sf) -
The following 4 links all contain useful information for working with spatial data. None have exercises to practice with, but they all have great examples to copy/paste and run (some of the examples above come from these documents). Please skim read each document, and execute some of the examples from each.
-
As you have time, here are some exercises you might consider attempting.
- Make a map that consists of the 48 contiguous states.
- Pick a state and draw a map of that state.
- Pick another country, and construct a map of that country. (You may need to locate another package that has this information)
- Explore
coords_sfto zoom in on one of your maps, or to adjust the projection. If you are familair with projections, you may want to follow the links the second reading above for more information.
Push your work to your GitHub repo. Pick at least two examples you would like to discuss with your team.
5.7 Task: US Cities
We will use library(USAboundaries) and library(sf) to make a map of the US and show the 3 largest cities in each state. Specifically, we will use library(ggplot2) and the function geom_sf() to recreate the provided image.
Usually we view our charts inside .Rmd or .html files, but there may be times when you need to save a chart as a separate image to include in a report or presentation. For this task, we are going to save our map as a .png file.
-
Create a chart that closely matches the example below.
- Remember that R has some helpful variables called
state.nameandstate.abb - Try setting
fill = NAin geom_sf() - Note that
library(USAboundaries)has three useful functions -us_cities(),us_states(), andus_counties() - To add the labels to the image consider using
library(ggrepel) - Note that the labels may not look correct until you save the map as a larger image.
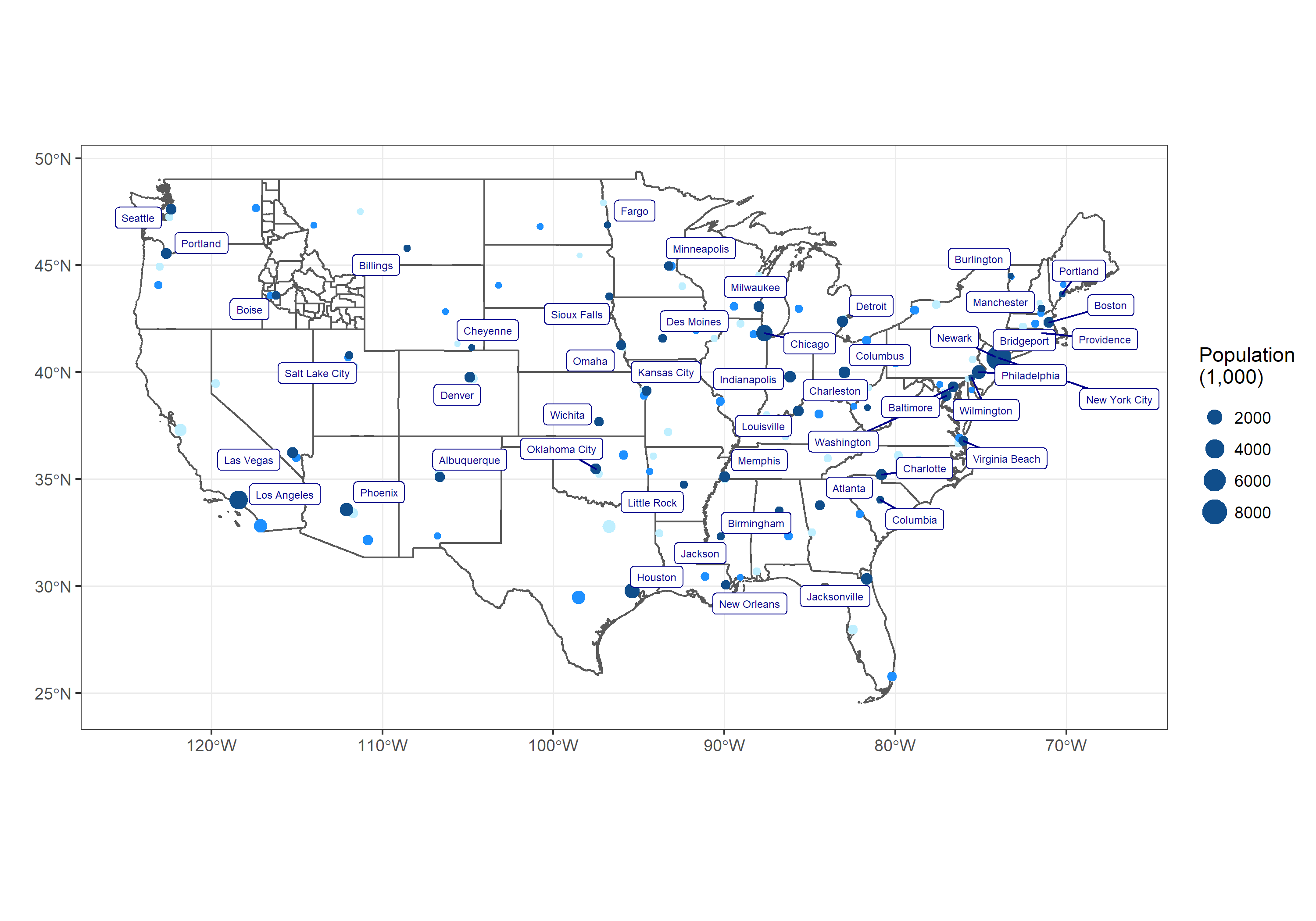
- Remember that R has some helpful variables called
Save your chart as a
.pngimage. Try usingggsave()withwidth = 15andheight = 10. What happens if you change the width and height?With any remaining time, try turning your map into a choropleth with colors representing total land area of each state.
5.8 Task: Getting in SHP
We have been asked by the state of Idaho to visualize permitted well locations with a production of more than 5000 gallons and the spatial relationship of the large wells to the locations of large dams (surface area larger than 50 acres). They have provided a shp file of US county boundaries, and have given us a web address for the well, dam, and water locations. They would like to have the Snake River and Henrys Fork rivers plotted.
-
Read in all four of the necessary shp file datasets (links above).
- Note: For these shp files it may not be possible to read them in directly from a url. If you run into issues, try manually downloading the data and importing it from your computer.
Filter all the data for the specific needs of Idaho.
Create a .png image that plots the required information asked for in the background section.
-
Use the code below to edit the geometry of the county boundaries shp file. Then recreate the plot from from the previous question with this new data. What do you notice?
library(USAboundaries) id_projection <- state_plane("ID") id_projection new_idaho_data <- st_transform(idaho_data, id_projection)
5.9 Task: Begin Case Study 8
Each case study throughout the semester will ask you to demonstrate what you’ve learned in the context of an open ended case study. The individual prep activity will always include a “being” reading which will lead to an in class discussion.
Complete the Being Reading section of Case Study 8. This will require that you read an article(s), and come to class with two or three things to share.
Download the data for the case study and begin exploring it. Your goal at this point is to simply to understand the data better. As needed, make charts and or summary tables to help you explore the data. Be prepared to share any questions you have about the data with your team.
Identify what visualizations this case study wants you to create. For each visualization, construct a paper sketch, listing the aesthetics (x, y, color, group, label, etc.), the geometries, any faceting, etc., that you want to appear in your visualization. Then construct on paper an outline of the table of data that you’ll need to create said visualization. You do not need to actually perform any computations in R, rather create rough hand sketches of the visualization and table that you can share with your team in class.
With any remaining time, feel free to start transferring your plans into code, and perform the wrangling and visualizing with R.
5.10 Task: dyGraphs and Time Series
Your data science income has ballooned, and you need to find somewhere to invest money you have saved. You have a savvy investment friend that is kind enough to tell you about some stocks they have been watching during the last year. You will need to visualize the performance of these stocks over the last five years to help in the conversation with your friend.
However, your friend is not going to tell you the stock symbols until the beginning of your half-hour meeting (they are a busy friend). You need to program an .Rmd file that will automatically build a suite of visualizations for any stocks they give you.
In today’s task, we’ll use both library(ggplot2) and library(dygraphs) to accomplish this goal. The dygraphs for R package requires we use an xts objects, rather than a data frame, to plot data. As such, we’ll need a conversion tool, available in the timetk package.
Load both
library(tidyverse)andlibrary(dygraphs), installing the latter if needed.-
Let’s look at an example where some data has been wrangled to use in
ggplot. The data we’ll examine contains two years of the adjusted closing stock prices for Amazon, Microsoft, and Walmart. The code below reads in the data, and produces 2 plots.my_stocks_gg <-read_csv("https://byuistats.github.io/DS350_2022/files/stocks_ggplot_ready.csv") my_stocks_gg %>% ggplot(aes(x = date, y = adjusted, color = symbol)) + geom_line() my_stocks_gg %>% group_by(symbol) %>% mutate(rebased_adj = adjusted / adjusted[1]) %>% ggplot(aes(x = date, y = rebased_adj, color = symbol)) + geom_line()What are the differences between the two plots created above? What value, if any, does the mutated column
rebased_adjprovide? -
Now let’s look at an example where data has been wrangled to use in
dygraphs. This is the same data, just in a different form. Thedygraphsfunction requires that our data be anxtsorzooobject (special time series formats). The code below reads in the data, converts the data frame into anxtsobject, and then constructs an interactive visualization.my_stocks_dy <-read_csv("https://byuistats.github.io/DS350_2022/files/stocks_dygraph_ready.csv") #Convert data to xts object my_xts <- timetk::tk_xts(data = my_stocks_dy, select = c(-date), date_var = date) #Plot the xts object. my_xts %>% dygraph() %>% dyRebase(value = 1) #The class function will show you what type of object each variable is. class(my_stocks_dy) class(my_xts)Spend a minute or two examining the differences between the
my_stocks_dyandmy_stocks_ggvariables. What’s different about how the data is stored. -
Let’s now pull current stock information from the web using
library(tidyquant). The commandtq_get(c("AMZN","MSFT","WMT"))will pull the last 10 years of daily stock information for Amazon, Microsoft, and Walmart. Pick your own set of 2-10 stocks and use thetq_get()function fromlibrary(tidyquant)to pull the last 10 years of data.- Wrangle the data (keep the last 2 years) and prepare it for use in ggplot. Then construct a visualization with
ggplotto compare your chosen stocks. - Wrangle the data (keep the last 2 years) and prepare it for use in dygraphs. Then construct a visualization with
dygraphsto compare your chosen stocks.
- Wrangle the data (keep the last 2 years) and prepare it for use in ggplot. Then construct a visualization with
The dygraphs package is an excellent resource for those heading into the finance sector. With any remaining time, explore the options available in the dygraphs for R Package. Head to that website, play with the examples there, and add on features to your stock visualization that seem useful. A range selector, for example, could be a great addition.
5.11 Task: Interactive Maps
The leaflet package in R allows us to make interactive charts. This introduction comes from the leaflet documentation:
Leaflet is one of the most popular open-source JavaScript libraries for interactive maps. It’s used by websites ranging from The New York Times and The Washington Post to GitHub and Flickr, as well as GIS specialists like OpenStreetMap, Mapbox, and CartoDB.
This R package makes it easy to integrate and control Leaflet maps in R.
-
Spend about 15 minutes looking through the leaflet documentation and reading through examples. I recommend these three pages in particular:
Using the documentation as a guide, try to recreate one of our previous map tasks using
leaflet. Try matching outlines, colors, shapes, etc.Now come up with your own map. You could create a map of your favorite restaurants in Rexburg, complete with popups. Or perhaps a map of every temple in the world!
5.12 Task: Intro to Machine Learning in R
This introduction will use the Colorado housing classification problem from CSE 250: Project 4. If you have not taken CSE 250, you may wish to click on the project link and read the background section.
There are many packages in R that will allow you to analyze your data with machine learning methods such as decision trees, random forests, neural networks, k-nearest neighbors, etc. Because each package was written by different authors the syntax of the functions varies greatly from package to package. This makes it difficult to jump between machine learning methods.
The focus of this introduction will be on tidymodels, which is a collection of packages (similar to the tidyverse) designed to streamline and unify the framework between many of R’s machine learning packages. We will be following the steps in this blog post but using our own data.
Install and load the
tidymodelspackage. Lodingtidymodelsmay force you to update many other packages.-
Use this code to load the
dwellings_ml.csvdata from CSE 250.library(readr) dwellings <- read_csv('https://github.com/byuidatascience/data4dwellings/raw/master/data-raw/dwellings_ml/dwellings_ml.csv') dwellings <- dwellings %>% select(-parcel, -yrbuilt) colnames(dwellings) <- make.names(colnames(dwellings)) dwellings$before1980 <- factor(dwellings$before1980) glimpse(dwellings) -
We start by splitting the data into training and testing sets. In tidy models, this is done using the
initial_split()function: -
If you read the background of Project 4, you’ll remember that our goal is to predict if house was built before 1980, or during/after 1980. Let’s train a random forest model to make this prediction.
dwellings_rf <- rand_forest(trees = 100, mode="classification") %>% set_engine("randomForest") %>% fit(before1980 ~., data = dwellings_training)In this code,
set_engine()is tellingtidymodelswe want to use therandomForestpackage to train our random forest model. Choosing to use a different package to train our model is as simple as switching the engine. In this scenario we could use therangerpackage orsparkpackage. Visit this website to explore other model and package options. -
How well does our model perform on the testing data set? Let’s calculate the accuracy and look at a confusion matrix. We’ll start by asking the model to make predictions for us.
predict(dwellings_rf, dwellings_testing)These predictions don’t tell us much on their own. Let’s join the predictions to our testing data. That way we’ll have the correct answers
before1980and the predictions.pred_classin the same tibble.Now we can run different evaluation metrics to assess performance. Run the code below. What do you learn from the output?
Now that you’ve seen an example of
tidymodelswith a random forest, pick another type of classification model and see if you can run it in R. Go to this page and look at all the models where themodeis “classification” to see your options. You can click on themodel typeto see documentation and code examples.
5.13 Task: Finish Case Study 7
Finish Case Study 7 and submit it. There is no other preparation task. The goal is to free up time to allow you to focus on and complete the case study.
5.14 Task: Improve a Previous Task
- Choose an old task you got stuck on, or would like to develop further. Spend this prep time improving the old task.
- Push your work to GitHub so you can share it with your classmates.
- Be prepared to share something new you learned, or something you still have questions about.
5.15 Task: Finish Case Study 8
Finish Case Study 8 and submit it. There is no other preparation task. The goal is to free up time to allow you to focus on and complete the case study.
5.16 Task: Practice Coding Challenge
- Find a place where you can focus for 1 hour on the coding challenge. Make sure you have everything you need (laptop charger, water bottle, etc.)
- When you are ready begin, go to our class I-Learn page for the instructions. You will submit your work in I-Learn.
- During class, we’ll have a discussion about the coding challenge.