2 Basic Wrangling and Visualizations
The tasks in this unit will help prepare you to do the following:
Use the grammar of graphics with ggplot to construct visualizations, selecting appropriate aestheics, geometries, scales, facets, etc.
Use appropriate functions from dplyr to transform and wrangle your data.
Adjust theme elements to construct publication ready visualizations.
The case studies, which appears at the end of this unit, give you an opportunity to demonstrate mastery of the objectives above.
2.1 Task: Visualization Reading
R for Data Science is an online textbook written by Hadley Wickham and Garrett Grolemund. It is an excellent resource that our course will reference often.
- Read R4DS Chapter 3: Data Visualization. As you read, aim to complete at least two practice exercises from each section. Get as far as you can in one hour. You are welcome to perform your computations in a script (
.R) or markdown (.Rmd) file. These ggplot2 tutorial videos may be useful as well. - When you are done, remember to push all your work to your class GitHub repo. Pick at least two exercises that you would like to discuss with your team (perhaps ones that were very helpful, or very difficult). Be prepared to share them with your team.
During class, make sure you can locate your peers work in GitHub. Feel free to use Slack to send each other links to your relevant files. Then go around in a circle, and have each team member share their selected exercises and what they learned.
2.2 Task: Fix This Chart
The Research & Creative Works Conference is held every semester at BYU-Idaho. University administrators would like to track student participation in the conference to help them prepare for future semesters. The data have already been collected and attempts have been made to visualize conference trends. You can see the data and charts in this Excel file.
A 3D column chart is a poor way to visualize data. Your task is to make a new chart that does a better job of answering the question: How has R&CW attendance changed over time within each department?
-
Start an RMarkdown file, and edit the YAML (the header at the top) so that the
.mdis kept during knitting. Your YAML could look like the one below (feel free to copy/paste):--- title: "Task 2.02 - Fix this chart" author: "Your Name" date: "`r format(Sys.time(), '%B %d, %Y')`" output: html_document: keep_md: true toc: true toc_float: true code_folding: hide --- -
Copy and paste this code into an R chunk to load in the conference data:
-
Use what you learned from the last task to create your own chart showing R&CW attendance trends over time.
- Remember you can view help pages for functions you don’t understand, such as
?geom_line(). There are examples at the end of every help file that you may find useful.
- Remember you can view help pages for functions you don’t understand, such as
Write a short description of the trends you see in your chart.
Knit your
.Rmdfile. This will automatically generate an.mdfile, a.htmlfile, and folder containing any images you created.Push your
.Rmd,.md,.html, and image folder to your GitHub repo.
During class, go around in a circle and have each team member share their chart and description, using their .md file from GitHub. A successful stuck is a perfectly valid thing to share (and hopefully you can help one another get unstuck in class). If you did not prepare for class, be honest with your teammates, learn from them, and commit to doing better.
2.3 Task: Exploring the gapminder Package
Data Expert
An important first step in answering business problems is becoming familiar with the data. Often you will want to start with the data dictionary. However, you can also just dive into the data and gain understanding based on the variable names and types.
It is also important to understand the relationships between variables. We can create tables or visualizations that summarize how different variables relate to each other. At this point we are deepening our understanding as well as beginning our analysis.
Remember: Your job is to become the data expert, not the domain expert. You will build domain skills but you are not going to replace domain experts. People will depend on you to have a firm understanding of what data your company has available to answer domain specific questions.
The Gapminder Data
Hans Rosling is one of the most popular data scientists on the web. His original TED talk set a new bar for data visualization. We are going to create some graphics using his formatted data.
Tasks
Watch Hans Rosling’s original TED talk. Come to class with 2 or 3 insights from the video that you can share with your team and/or class.
-
Install and load the
gapminderpackage, which contains thegapminderdataset, along with loadingtidyverse. -
Explore the data set, to get a feel for what’s available. Create a new
.Rmdfile (so your visualizations will show on GitHub in the.mdfile). Then explore the data.- Pick a quantitative variable and create a chart that summarizes the distribution.
- Pick a qualitative variable and create a chart that summarizes the distribution.
- Pick two variables and create a chart that summarizes the bivariate distribution (the relationship between the two).
- Try using color, shape, alpha, facets, etc., to visualize the relationships among 3 or more variables.
- Use the rest of your preparation time for this task to repeat the above on various variables.
Here is an example of exploring the continent variable with a bar graph.
Knit your
.Rmdfile, saving the.mdfile, and push your work to your GitHub repo (make sure you can see your images when viewing your.mdfile on github.com).
During class, go around in a circle and have each team member share, using their .md file from GitHub, one or two visualizations they made during their exploratory data analysis. If any new questions in the EDA (exploratory data analysis) phase, answer them together.
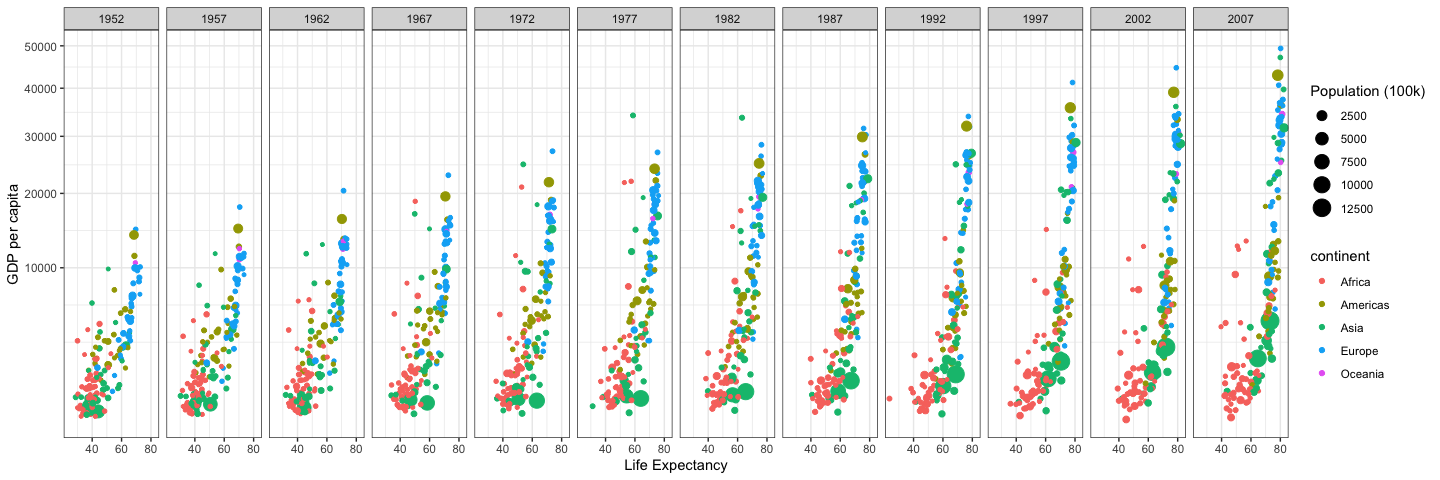
2.4 Task: Gapminder - Recreate a Visualization
In this task we’ll use ggplot() to recreate a visualization that illustrates the relationships among all 6 variables in the gapminder data set.
Create a new R Markdown file. Load the
tidyverseandgapminderpackages.-
Recreate the graphic shown below (get them to match as closely as you can). Try to get every aspect of the graphic to match what you see. Feel free to open the graphic in a new tab, and zoom in, if needed.
Use
library(tidyverse)to loadggplot2anddplyr.-
Note that we need to remove Kuwait from the data (discussion on this). We can remove Kuwait from the data, using the
filter()command fromdplyr, as follows. You’ll need
theme_bw()to get the correct background.Use
scale_y_continuous(trans = "sqrt")to get the correct scale on the y-axis.Use
ggsave()and save the plot as a.pngfile with a width of 15 inches.
Knit your
.Rmdfile, and push your work (including the.mdfile, associated image directory, and saved.pngfile) to your class GitHub repository.
During class, go around in a circle and have each team member share their work, using their files from GitHub. Make note of any differences you see between your graphics and the one above, and work to help each other resolve any issues.
2.5 Task: Data Transformation Reading
Often we’ll need to tranform data from one form to another. The dplyr package (which automatically gets loaded with tidyverse) will provide us with almost all the tools we’ll need. RStudio maintains a repository of cheatsheets. The data transformation cheatsheet can help us quickly remember things we learn in the reading below.
Read R4DS Chapter 5: Data Transformation. As you read, do at least two the practice exercises from each of section. Get as far as you can in one hour. You are welcome to perform your computations in a script (
.R) or markdown (.Rmd) file.When you are done, remember to push all your work to your class GitHub repo. Pick at least two exercises that you would like to discuss with your team (perhaps ones that were very helpful, or very difficult). Be prepared to share them with your team.
During class, make sure you can locate your peers work in GitHub. Feel free to use Slack to send each other links to your relevant files. Then go around in a circle, and have each team member share their selected exercises and what they learned.
2.6 Task: The Great British Bake Off
The Great British Bake Off is a hit reality TV show where amateur bakers compete against each other. Contestants are eliminated in each round until a winner is crowned. The show has run for 12 series (what we call “seasons” in the United States) through 2021, with plenty of drama. We will analyze the TV ratings of the first 10 series of the show.
-
Read in the TV ratings data for the show using the following code. We will be using the
ratingsdataset. You can learn more about the data set by running?ratings.install.packages("remotes") remotes::install_github("apreshill/bakeoff") library(bakeoff) -
Copy the code below into your
.Rmdfile and study it line by line. Add a comment to each line that explains what that particular line/function is doing. Now create a new dataframe called
ratings_10that filters theratingsdata to keep series with exactly 10 episodes. Add a new variable that calculates the mean ofviewers_7dayfor each series.-
Use the
only_first_lastdata to create a chart that compares the ratings for the premier and finale of each series.- Write a short description of the trends you see in your chart.
-
Use the
ratings_10data to create a chart that displaysviewers_7dayfor each episode per series, and also shows how mean ofviewers_7daychanges across series.- Write a short description of the trends you see in your chart.
Knit your
.Rmdfile and push your files to GitHub.Be prepared to share your charts and descriptions with your team.
During class, go around in a circle and have each team member share something from the individual prep. (You can view their .md file on GitHub.) Discuss what patterns or outliers you see in the charts. (A quick internet search might help explain them.) Help each other improve wrangling or visualizations.
2.7 Task: dplyr and Gapminder - Part 1
Hans Rosling was one of the most popular data scientists on the web. His original TED talk set a new bar for data visualization. We are going to create the graphic below using his formatted data.
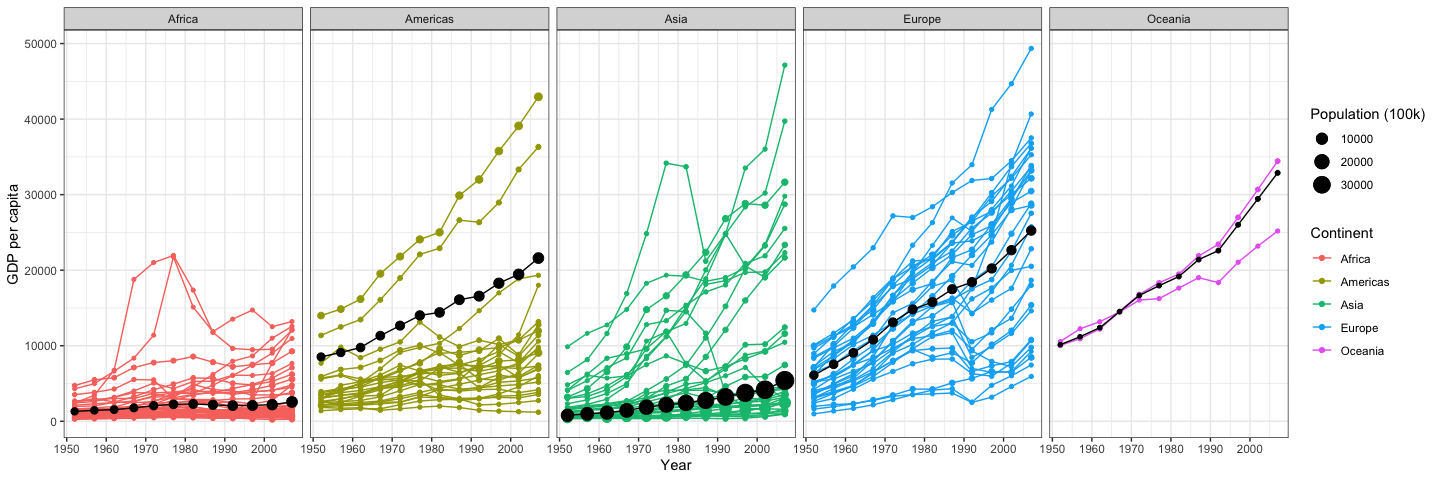
Note that we need to remove Kuwait from the data.
- Recreate the graphic shown above using the gapminder dataset from
library(gapminder)(get your visualization to match as closely as you can).- Remove Kuwait from the data.
- Use
library(tidyverse)to loadggplot2()anddplyr(). - Use
theme_bw(). - The black lines and dots are the continent average GDP, weighted by the population of that continent. You can build a weighted average data set using
weighted.mean()withsummarise()andgroup_by().
- Place your work in a .Rmd file, knit it, and upload your work to GitHub to share with your team.
2.8 Task: dplyr and Gapminder - Part 2
This task builds upon the previous, but this time you get to choose what kind of charts will best answer the question at hand. We will focus on only 3 continents (Africa, Americas and Asia). Our goal is to visualize life expectancy over time.
Note that R users have put together a collection of cheat sheets to help each others remember key commands in commonly used packages.
For your work today, some of the following commands may prove useful.
-
filter(),arrange(),desc(),select(),mutate(),group_by(),top_n(),slice(),summarise(),lag()
- Load
library(tidyverse)andlibrary(gapminder). Remove Kuwait from the data.
- We’ll now wrangle the data a bit more.
- Filter the data to include only the continents Africa, Americas, and Asia.
- Within each continent find which country had the largest overall increase in life expectancy from 1952 to 2007. This should give you 3 countries. Include a visualization to help validate your choice of countries.
- Within each continent find which country had the smallest overall increase (or even a decrease) from 1952 to 2007. This should give you another 3 countries. Include a visualization to help validate your choice of countries.
- Filter the data to include only the continents Africa, Americas, and Asia.
- Display these 6 country’s life expectancy as it has changed over the years.
- Create an R Markdown report that includes the wrangling and visualizations above. Knit the document, and share your work in GitHub.
2.9 Task: Begin Case Study 1
It’s time to focus on the final step in the BYU-I learning model, ponder and prove. Each case study throughout the semester will ask you to demonstrate what you’ve learned in the context of an open ended case study. The individual prep activity will always include a being reading which will lead to an in class discussion.
Complete the Being reading section of Case Study 1. This will require that you read the entire article, and come to class with two or three things to share.
There are three questions to address in this case study. Pick one of the questions and then on paper, create a rough sketch of a visualization you believe would answer the question. List the aesthetics (x, y, color, group, label, etc.), the geometries, any faceting, etc., that you want to appear in your visualization. Then construct on paper an outline of the table of data that you’ll need to create said visualization. So draw a table, list the column names, and identify any mutations or summaries you’ll need to perform on the
flightsdata set to obtain this table. You do not need to actually perform any computations in R, rather create rough hand sketches of the visualization and table that you can share with your team in class.Repeat the previous item with the other two questions. This is the planning phase of your wrangling and visualization. You’ll share your rough sketches with each other in class.
With any remaining time, feel free to start transferring your plans into code, and perform the wrangling and visualizing with R.
2.10 Task: Graphics for Communication Reading
Read R4DS Chapter 28: Graphics for Communication. As you read, do at least two practice exercises from each section. Get as far as you can in one hour. You are welcome to perform your computations in markdown
.Rmdfile, so you can share you.mdfile in class.When you are done, push your work to your GitHub repo. Then pick at least two exercises you would like to discuss (perhaps ones that were very helpful, or very difficult). Be prepared to share them with your team.
2.11 Task: Our World In Data
The Our World in Data website publishes research and graphics that provide insight into world data. We are going to recreate one of their charts and use it to practice our annotation skills.
Creating custom, stylized ggplot2 themes can get complicated very quickly. Finding answers and examples on Google is easier if you know what key words to search for. These resources might be helpful as you begin to learn ggplot2 lingo.
If the thing you want to edit is not a theme element, then it must be related to data and can mostly likely be changed inside a geom_*() or a scale_*() layer.
- Recreate this graph as closely as you can.
- The data is provided on the download tab.
- Focus your energy on labels, the y-axis, background color, and line color.
- If you are getting stuck matching the graph, try completing steps 2 and 3, then coming back to this step with the time you have left.
- Suppose we wanted to highlight (draw attention to) any points that are above 100%. Create two more graphs that show two different ways to highlight these points.
- Make one more graph that adds a line for the United States. Try highlighting the United States line using what you learned from the textbook.
- Save your code and plots in an
.Rmdfile. Knit and push all your knitted files to GitHub. - Be prepared to discuss with your team the pros and cons of each highlighting method you tried.
2.12 Task: Begin Case Study 2
Each case study throughout the semester will ask you to demonstrate what you’ve learned in the context of an open ended case study. The individual prep activity will always include a “being” reading which will lead to an in class discussion.
Complete the Being Reading section of Case Study 2. This will require that you read both articles, and come to class with two or three things to share.
Download the data for the case study and begin exploring it. Your goal at this point is not to find a seasonal trend, but simply to understand the data better. For each variable, make one chart or table that summarizes the distribution. Be prepared to share any questions you have about the data with your team.
This case study has you searching for seasonal trends in gun deaths. Pick one or two variables from the data, and then on paper create a rough sketch of a chart you think would show seasonal patterns. List the aesthetics (x, y, color, group, label, etc.), the geometries, any faceting, etc., that you want to appear in your visualization. Then construct on paper an outline of the table of data that you’ll need to create said visualization. You do not need to actually perform any computations in R, rather create rough hand sketches of the visualization and table that you can share with your team in class.
With any remaining time, feel free to start transferring your plans into code, and perform the wrangling and visualizing with R.
2.13 Task: Finish Case Study 1
Finish Case Study 1 and submit it. There is no other preparation task. The goal is to free up time to allow you to focus on and complete the case study.
2.14 Task: Our World in Data - Choose your own
- Explore the articles published on Our World in Data. Find a chart with a message that interests you, and that you would like to recreate.
- Download the data for the chart (each chart has a “download” tab) and use your
ggplot2skills to recreate the chart as closely as you can. - Push your work to GitHub so you can share it with your classmates.
- Be prepared to share something new you learned, or something you got stuck on.
2.15 Task: Improve a Previous Task
- Choose an old task you got stuck on, or would like to develop further. Spend this prep time improving the old task.
- Push your work to GitHub so you can share it with your classmates.
- Be prepared to share something new you learned, or something you still have questions about.
2.16 Task: Finish Case Study 2
Finish Case Study 2 and submit it. There is no other preparation task. The goal is to free up time to allow you to focus on and complete the case study.