{kind=link}
R/R-Studio Help
Introduction
R-Studio and Rmarkdown First Use: After you have installed R and R-Studio then this page will help you with building your first .Rmd file. We will use this type of file heavily throughout the semester. For those of you less familiar with R use the information below to get up to speed.
Rmd Template
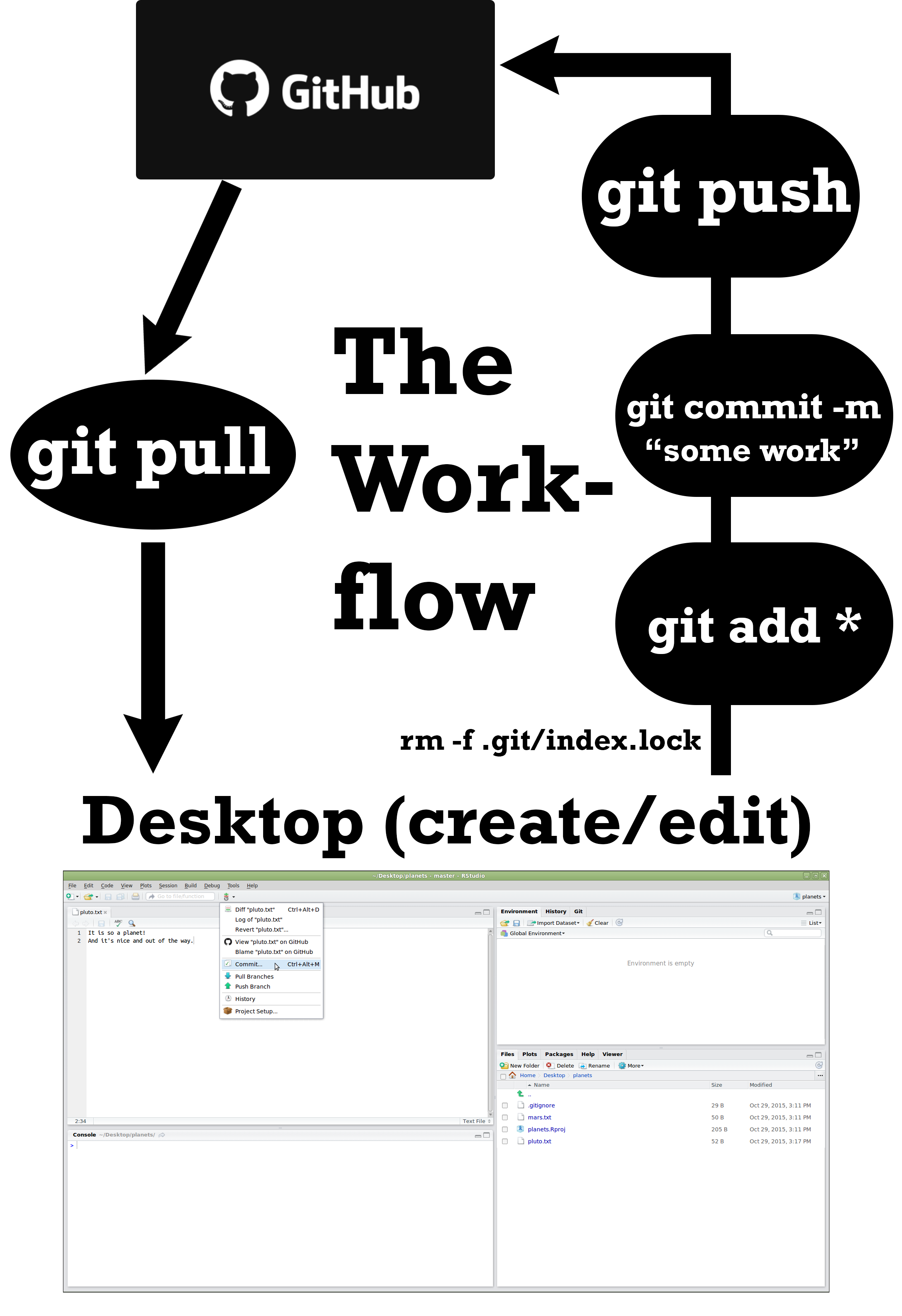
We have built a template .Rmd file that you can use for our course. It will build the YAML that we would prefer for this course. It requires that you install a package from a GitHub repository. I have listed the steps below.
- Use
devtoolspackage in R and install Dylan’s package.
install.packages("devtools")
devtools::install_github("dylanjm/Rtemplates", subdir = "StatsBYUI")- Now in R-Studio create a new
R Markdown ...and then chooseFrom Template. - There should be an option that says
Math 335 Analysis. Select it and clickOK.
Additional links
- R Cheat Sheets: This page has links to one-page guides to different R packages and data science tools.
- Google’s R Style Guide: A guide from Google on how to type clean code that allows your code to communicate with others. Think Elements of Style.
- R Visualization: Some random links about R packages for visualization.
R language background
Beyond being FREE and the predominate statistical software used in science, industry, research, and business, it has great pedagogical advantages. Daniel Kaplan summarized a great learning/teaching advantage of using R in the following quote.
In mathematics and statistics, the output of one computation often becomes the input to another computation. That’s why math courses spend so much time talking about functions (and “domain” and “range”, etc.). In word processing, whenever you highlight a word and move it or change the font or replace it, you still end up with stuff on which you can perform the same operations: highlighting, moving, font-changing, etc. Not so in math and statistics. The sorts of operations that you will often perform - solving, integration, statistical summaries, etc. - produce a new kind of thing on which you will be performing new kinds of operations. In mathematics and statistics, you create a chain of operations and you need to be able to express the steps in that chain. It’s not a question of having enough buttons to list all the operations, you’ll need combinations of operations - more than could possibly be listed in a menu system.1
For those of you coming from a computer science background, John D. Cook provides some useful insight2
I have written software professionally in perhaps a dozen programming languages, and the hardest language for me to learn has been R. The language is actually fairly simple, but it is unconventional.
We can also track the competition between R and Python here.
For those of you coming from a business or engineering background, you should know that the difficulty of coding in Excel has contributed to some serious blunders in globally impactful discussions [1,2,3] and has serious flaws in how data are even handled.
Below are some references from reputable online sources about the impact and usefulness of R.
- Fast Company Article on R
- “R can do literally everything, and all new research is done in R. So especially for businesses that really want to out-compete their competitors on the basis of advanced analytics, they can get access to everything they need within R, things that might not come for five or 10 years through commercial software,” says Smith.
- New York Times on R
- “The great beauty of R is that you can modify it to do all sorts of things,” said Hal Varian, chief economist at Google. “And you have a lot of prepackaged stuff that’s already available, so you’re standing on the shoulders of giants.”
- InfoWorld
- Still, Adams and Peng both see R as an accessible language. “I don’t come from a computer science background and never had aspirations of becoming a programmer. Knowledge of programming fundamentals certainly helps when adding R to your toolbox, but I wouldn’t say it’s required to get started,” Adams says.
- “I wouldn’t even say R is for programmers. It’s best suited for people that have data-oriented problems they’re trying to solve, regardless of their programming aptitude.”
Learning R
We will spend time during class all semester learning new syntax. During the first two weeks we will spend a little more time learning the basics of R and how to use it (often the most challenging). Daniel Kaplan’s book also has a nice introduction.
R, R-Studio, .Rmd files, and .R scripts
We will need to install R, R-Studio, and get comfortable with .Rmd files and .R files.
R
- The R website is where we can go to find the latest version to download for your particular operation system.
- Here is a video for Mac users and Windows users. There is also a Linux version of R as well.
.R Scripts
.Rscript files are the typical file type for saving yourRscripts. This is often the file I start with for any analysis. In fact, if you have experience with.Rmdfiles, you can write an.Rscript in such a way that it can be built into an html page like an.Rmdfile. See here.
R-Studio & Rmd Files
- R-Studio is a great software to facilitate the use of R (and many other things). We will use R-Studio heavily in this course! Please download R-Studio.
.Rmdfiles are the passport to a full space of data presentation opportunities. Here is an overview of R Markdown and its use in R-Studio. Finally, here is a short tutorial to get yourself up and running with R Markdown.
R Help Files
Basics of working with R at the command line and RStudio goodies
Launch RStudio/R.
Notice the default panes:
- Console (entire left)
- Environment/History (tabbed in upper right)
- Files/Plots/Packages/Help (tabbed in lower right)
FYI: you can change the default location of the panes, among many other things: Customizing RStudio.
Go into the Console, where we interact with the live R process.
Make an assignment and then inspect the object you just created.
x <- 3 * 4
x## [1] 12All R statements where you create objects – “assignments” – have this form:
objectName <- valueand in my head I hear, e.g., “x gets 12”.
You will make lots of assignments and the operator <- is a pain to type. Don’t be lazy and use =, although it would work, because it will just sow confusion later. Instead, utilize RStudio’s keyboard shortcut: Alt + - (the minus sign).
Notice that RStudio automagically surrounds <- with spaces, which demonstrates a useful code formatting practice. Code is miserable to read on a good day. Give your eyes a break and use spaces.
RStudio offers many handy keyboard shortcuts. Also, Alt+Shift+K brings up a keyboard shortcut reference card.
Object names cannot start with a digit and cannot contain certain other characters such as a comma or a space. You will be wise to adopt a convention for demarcating words in names.
i_use_snake_case
other.people.use.periods
evenOthersUseCamelCaseMake another assignment
this_is_a_really_long_name <- 2.5To inspect this, try out RStudio’s completion facility: type the first few characters, press TAB, add characters until you disambiguate, then press return.
Make another assignment
jenny_rocks <- 2 ^ 3Let’s try to inspect:
jennyrocks## Error in eval(expr, envir, enclos): object 'jennyrocks' not foundjeny_rocks## Error in eval(expr, envir, enclos): object 'jeny_rocks' not foundImplicit contract with the computer / scripting language: Computer will do tedious computation for you. In return, you will be completely precise in your instructions. Typos matter. Case matters. Get better at typing.
R has a mind-blowing collection of built-in functions that are accessed like so
functionName(arg1 = val1, arg2 = val2, and so on)Let’s try using seq() which makes regular sequences of numbers and, while we’re at it, demo more helpful features of RStudio.
Type se and hit TAB. A pop up shows you possible completions. Specify seq() by typing more to disambiguate or using the up/down arrows to select. Notice the floating tool-tip-type help that pops up, reminding you of a function’s arguments. If you want even more help, press F1 as directed to get the full documentation in the help tab of the lower right pane. Now open the parentheses and notice the automatic addition of the closing parenthesis and the placement of cursor in the middle. Type the arguments 1, 10 and hit return. RStudio also exits the parenthetical expression for you. IDEs are great.
seq(1, 10)## [1] 1 2 3 4 5 6 7 8 9 10The above also demonstrates something about how R resolves function arguments. You can always specify in name = value form. But if you do not, R attempts to resolve by position. So above, it is assumed that we want a sequence from = 1 that goes to = 10. Since we didn’t specify step size, the default value of by in the function definition is used, which ends up being 1 in this case. For functions I call often, I might use this resolve by position for the first argument or maybe the first two. After that, I always use name = value.
Make this assignment and notice similar help with quotation marks.
yo <- "hello world"If you just make an assignment, you don’t get to see the value, so then you’re tempted to immediately inspect.
y <- seq(1, 10)
y## [1] 1 2 3 4 5 6 7 8 9 10This common action can be shortened by surrounding the assignment with parentheses, which causes assignment and “print to screen” to happen.
(y <- seq(1, 10))## [1] 1 2 3 4 5 6 7 8 9 10Not all functions have (or require) arguments:
date()## [1] "Sat Sep 12 16:46:46 2020"Now look at your workspace – in the upper right pane. The workspace is where user-defined objects accumulate. You can also get a listing of these objects with commands:
objects()## [1] "a" "avg_x" "b"
## [4] "background.title" "build_table" "cases"
## [7] "class_cs" "class_reading" "class_task"
## [10] "current" "d" "dat"
## [13] "date_table" "dates_all" "dates_class"
## [16] "day_seq" "dnumber" "ff"
## [19] "fname" "fname_c" "full_service_names"
## [22] "full_service_type" "ggp" "ggpoint"
## [25] "glevel" "i" "jenny_rocks"
## [28] "last_day_finals" "list_object" "mark_holidays"
## [31] "md_bullet" "md_link" "mw_table"
## [34] "no_cores" "not_restaurants" "number"
## [37] "pr" "quick_service_names" "quick_service_type"
## [40] "readings" "readings_due" "se"
## [43] "se_tt" "semester" "semester_print"
## [46] "sequence_dates" "sequence_se" "sequence_se_tt"
## [49] "sig_sq" "standalone_retail" "startend_dates"
## [52] "task_due" "tasks" "teacher_url_add"
## [55] "text" "text_c" "this_is_a_really_long_name"
## [58] "title.text" "tt_table" "vals"
## [61] "week_10" "week_11" "week_12"
## [64] "week_13" "x" "y"
## [67] "year_print" "yo"ls()## [1] "a" "avg_x" "b"
## [4] "background.title" "build_table" "cases"
## [7] "class_cs" "class_reading" "class_task"
## [10] "current" "d" "dat"
## [13] "date_table" "dates_all" "dates_class"
## [16] "day_seq" "dnumber" "ff"
## [19] "fname" "fname_c" "full_service_names"
## [22] "full_service_type" "ggp" "ggpoint"
## [25] "glevel" "i" "jenny_rocks"
## [28] "last_day_finals" "list_object" "mark_holidays"
## [31] "md_bullet" "md_link" "mw_table"
## [34] "no_cores" "not_restaurants" "number"
## [37] "pr" "quick_service_names" "quick_service_type"
## [40] "readings" "readings_due" "se"
## [43] "se_tt" "semester" "semester_print"
## [46] "sequence_dates" "sequence_se" "sequence_se_tt"
## [49] "sig_sq" "standalone_retail" "startend_dates"
## [52] "task_due" "tasks" "teacher_url_add"
## [55] "text" "text_c" "this_is_a_really_long_name"
## [58] "title.text" "tt_table" "vals"
## [61] "week_10" "week_11" "week_12"
## [64] "week_13" "x" "y"
## [67] "year_print" "yo"If you want to remove the object named y, you can do this
rm(y)To remove everything:
rm(list = ls())or click the broom in RStudio’s Environment pane.
Workspace and working directory
One day you will need to quit R, go do something else and return to your analysis later.
One day you will have multiple analyses going that use R and you want to keep them separate.
One day you will need to bring data from the outside world into R and send numerical results and figures from R back out into the world.
To handle these real life situations, you need to make two decisions:
What about your analysis is “real”, i.e. you will save it as your lasting record of what happened?
Where does your analysis “live”?
Workspace, .RData
As a beginning R user, it’s OK to consider your workspace “real”. Very soon, I urge you to evolve to the next level, where you consider your saved R scripts as “real”. (In either case, of course the input data is very much real and requires preservation!) With the input data and the R code you used, you can reproduce everything. You can make your analysis fancier. You can get to the bottom of puzzling results and discover and fix bugs in your code. You can reuse the code to conduct similar analyses in new projects. You can remake a figure with different aspect ratio or save is as TIFF instead of PDF. You are ready to take questions. You are ready for the future.
If you regard your workspace as “real” (saving and reloading all the time), if you need to redo analysis … you’re going to either redo a lot of typing (making mistakes all the way) or will have to mine your R history for the commands you used. Rather than becoming an expert on managing the R history, a better use of your time and psychic energy is to keep your “good” R code in a script for future reuse.
Because it can be useful sometimes, note the commands you’ve recently run appear in the History pane.
But you don’t have to choose right now and the two strategies are not incompatible. Let’s demo the save / reload the workspace approach.
Upon quitting R, you have to decide if you want to save your workspace, for potential restoration the next time you launch R. Depending on your set up, R or your IDE, eg RStudio, will probably prompt you to make this decision.
Quit R/Rstudio, either from the menu, using a keyboard shortcut, or by typing q() in the Console. You’ll get a prompt like this:
Save workspace image to ~/.Rdata?
Note where the workspace image is to be saved and then click Save.
Using your favorite method, visit the directory where image was saved and verify there is a file named .RData. You will also see a file .Rhistory, holding the commands submitted in your recent session.
Restart RStudio. In the Console you will see a line like this:
[Workspace loaded from ~/.RData]indicating that your workspace has been restored. Look in the Workspace pane and you’ll see the same objects as before. In the History tab of the same pane, you should also see your command history. You’re back in business. This way of starting and stopping analytical work will not serve you well for long but it’s a start.
Working directory
Any process running on your computer has a notion of its “working directory”. In R, this is where R will look, by default, for files you ask it to load. It also where, by default, any files you write to disk will go. Chances are your current working directory is the directory we inspected above, i.e. the one where RStudio wanted to save the workspace.
You can explicitly check your working directory with:
getwd()It is also displayed at the top of the RStudio console.
As a beginning R user, it’s OK let your home directory or any other weird directory on your computer be R’s working directory. Very soon, I urge you to evolve to the next level, where you organize your analytical projects into directories and, when working on project A, set R’s working directory to the associated directory.
Although I do not recommend it, in case you’re curious, you can set R’s working directory at the command line like so:
setwd("~/myCoolProject")Although I do not recommend it, you can also use RStudio’s Files pane to navigate to a directory and then set it as working directory from the menu: Session –> Set Working Directory –> To Files Pane Location. (You’ll see even more options there). Or within the Files pane, choose More and Set As Working Directory.
But there’s a better way. A way that also puts you on the path to managing your R work like an expert.
RStudio projects
Keeping all the files associated with a project organized together – input data, R scripts, analytical results, figures – is such a wise and common practice that RStudio has built-in support for this via its projects.
Let’s make one to use for the rest of this workshop/class. Do this: File > New Project …. The directory name you choose here will be the project name. Call it whatever you want (or follow me for convenience).
I created a directory and, therefore RStudio project, called swc in my tmp directory, FYI.
setwd("~/tmp/swc")Now check that the “home” directory for your project is the working directory of our current R process:
getwd()I can’t print my output here because this document itself does not reside in the RStudio Project we just created.
Let’s enter a few commands in the Console, as if we are just beginning a project:
a <- 2
b <- -3
sig_sq <- 0.5
x <- runif(40)
y <- a + b * x + rnorm(40, sd = sqrt(sig_sq))
(avg_x <- mean(x))## [1] 0.5476715write(avg_x, "avg_x.txt")
plot(x, y)
abline(a, b, col = "purple")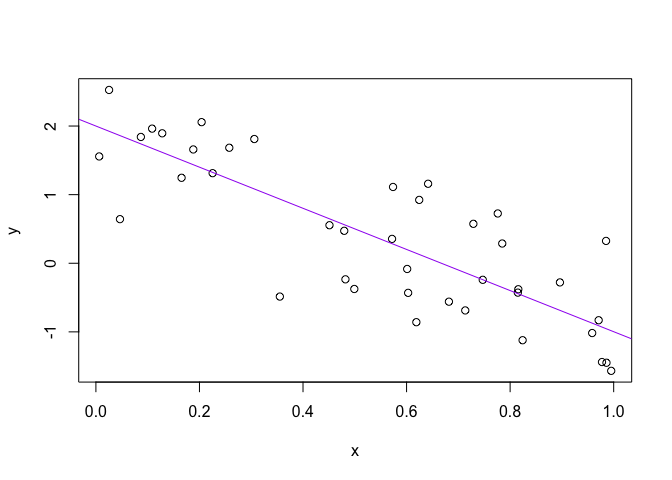
dev.print(pdf, "toy_line_plot.pdf")## quartz_off_screen
## 2Let’s say this is a good start of an analysis and your ready to start preserving the logic and code. Visit the History tab of the upper right pane. Select these commands. Click “To Source”. Now you have a new pane containing a nascent R script. Click on the floppy disk to save. Give it a name ending in .R or .r, I used toy-line.r and note that, by default, it will go in the directory associated with your project.
Quit RStudio. Inspect the folder associated with your project if you wish. Maybe view the PDF in an external viewer.
Restart RStudio. Notice that things, by default, restore to where we were earlier, e.g. objects in the workspace, the command history, which files are open for editing, where we are in the file system browser, the working directory for the R process, etc. These are all Good Things.
Change some things about your code. Top priority would be to set a sample size n at the top, e.g. n <- 40, and then replace all the hard-wired 40’s with n. Change some other minor-but-detectable stuff, i.e. alter the sample size n, the slope of the line b,the color of the line … whatever. Practice the different ways to re-run the code:
Walk through line by line by keyboard shortcut (command + enter) or mouse (click Run in the upper right corner of editor pane).
Source the entire document – equivalent to entering
source('toy-line.r')in the Console – by keyboard shortcut (shift command S) or mouse (click Source in the upper right corner of editor pane or select from the mini-menu accessible from the associated down triangle).Source with echo from the Source mini-menu.
Visit your figure in an external viewer to verify that the PDF is changing as you expect.
In your favorite OS-specific way, search your files for toy_line_plot.pdf and presumably you will find the PDF itself (no surprise) but also the script that created it (toy-line.r). This latter phenomenon is a huge win. One day you will want to remake a figure or just simply understand where it came from. If you rigorously save figures to file with R code and not ever ever ever the mouse or the clipboard, you will sing my praises one day. Trust me.
stuff
It is traditional to save R scripts with a .R or .r suffix. Follow this convention unless you have some extraordinary reason not to.
Comments start with one or more # symbols. Use them. RStudio helps you (de)comment selected lines with Ctrl+Shift+C (windows and linux) or Command+Shift+C (mac).
Clean out the workspace, ie pretend like you’ve just revisited this project after a long absence. The broom icon or rm(list = ls()). Good idea to do this, restart R (available from the Session menu), re-run your analysis to truly check that the code you’re saving is complete and correct (or at least rule out obvious problems!).
This workflow will serve you well in the future:
- Create an RStudio project for an analytical project
- Keep inputs there (we’ll soon talk about importing)
- Keep scripts there; edit them, run them in bits or as a whole from there
- Keep outputs there (like the PDF written above)
Avoid using the mouse for pieces of your analytical workflow, such as loading a dataset or saving a figure. Terribly important for reproducility and for making it possible to retrospectively determine how a numerical table or PDF was actually produced (searching on local disk on filename, among .R files, will lead to the relevant script).
Many long-time users never save the workspace, never save .RData files (I’m one of them), never save or consult the history. Once/if you get to that point, there are options available in RStudio to disable the loading of .RData and permanently suppress the prompt on exit to save the workspace (go to Tools->Options->General).
For the record, when loading data into R and/or writing outputs to file, you can always specify the absolute path and thereby insulate yourself from the current working directory. This is rarely necessary when using RStudio Projects properly.
R packages
One of the greatest features of R is the opensource development of additional functions that can be easily shared through libraries. We will use a wide variety of packages in this class. This page has a list of the primary packages we will be using in the class. All packages first need to be installed into your local version of R using install.packages("PACKAGENAMEHERE").
library(tidyverse) # loads ggplot2, tibble, tidyr, readr, purrr, dplyr
library(sf)
library(readxl)
library(haven)tidyverse
Our book leverages this wrapper package heavily. See tidyverse.org for details. It really is simple way to load the following packages. See each link for a description of the respective package. Running install.packages("tidyverse") installs many more packages (over 35).
sf
This packages provides functionality for handling spatial data objects. I learned R using the sp package and other packages that leveraged sp. As of last year there is a new package in town for handling spatial data. Read about it here and see the repository for details on the package.
readxl
This package is installed with `install.packages(“tidyverse”). The readxl package is the primary package we will use in class. It may be useful to know that tidyxl, or xlconnect provide much more comprehensive interaction with Excel workbooks. I have used the xlsx library as well. Note that the xlconnect and xlsx libraries require java be installed on your computers.
haven
This package is installed with `install.packages(“tidyverse”). There are three functions that make it easier to read SAS, SPSS, and Stata data files. Previously, I have used the foreign. See examples of foreign here