Machine Learning
Skill Builder
Machine Learning
Data
Intro to Titanic Machine Learning Skill Builder
For this skill builder, we’ll be putting our machine learning hats on. We’ll be creating a model that predicts whether a passenger survived. With machine learning, there is a lot of jargon! It can be quite overwhelming at times. This skill builder attempts to keep things basic and simple. With that being said, there are some terms that are important to understand. Let’s look at the first few rows of our dataset before proceeding with the definitions.
The titanic dataset will be used for examples of each definition.
| survived | pclass | sex | age | siblings_spouses_aboard | parents_children_aboard | fare |
|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 22 | 1 | 0 | 7.25 |
| 1 | 1 | 0 | 38 | 1 | 0 | 71.2833 |
| 1 | 3 | 0 | 26 | 0 | 0 | 7.925 |
| 1 | 1 | 0 | 35 | 1 | 0 | 53.1 |
| 0 | 3 | 1 | 35 | 0 | 0 | 8.05 |
Important Terms:
features: measurable property of the object you’re trying to predict. We use this information to predict our target of interest.- Example: pclass, sex, age, siblings_spouses_aboard , parents_children_aboard, fare columns are all examples of different features.
- Synonyms: attributes, explanatory variables, independent variables, variables, X’s, covariates
target: the feature that you are wanting to gain more insight into. The thing you are trying to predict.- Example: in the titanic dataset our target is survived
- Synonyms: label, dependent variable, y
train set: Usually 70% of the rows from the original dataset are randomly sampled to create this training data. It’s used by the algorithm, to determine, or learn, the optimal combinations of variables that will generate a good predictive model- Example: Random sample of 70% of the original titanic dataset rows
- Synonyms: training data, train data, X_train, y_train
test set: Usually the remaining 30% of the rows in the original dataset are used to create this dataset. The testing data is a set of rows used only to assess the performance (i.e. generalization) of a model. To do this, the final model is used to predict classifications of examples in the test set. Those predictions are compared to the examples’ true classifications to assess the model’s accuracy.- Example: Random sample of 30% of the original titanic dataset rows
- Synonyms: testing data, test data, X_test, y_test
evaluation metrics: A statistic that tells you how well your predictions align with the actual values. Other words, tells you how good your model is.- Example: Accuracy, Precision, Recall, MSE, MAE, Rsquared
- Synonyms: performance metric
Again, this is a very light and oversimplified treatment of machine learning. The purpose of this project is to help you understand the main concepts of ml and walk you through the process of building a machine learning model. A simplified work flow of a machine learning project is shown below. Spend some time getting familiar with this flow &mdash as you are about to code it… Exciting!
Note in order to do this skill builder you will need to have scikit-learn installed on your machine. Run the following command in your terminal if you haven’t already.
pip install scikit-learn
Exercise 1
Imports and Loading in Data
# Loading in packages
import pandas as pd
import numpy as np
import plotly.express as px
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Loading in data
data = pd.read_csv(___)Exercise 2
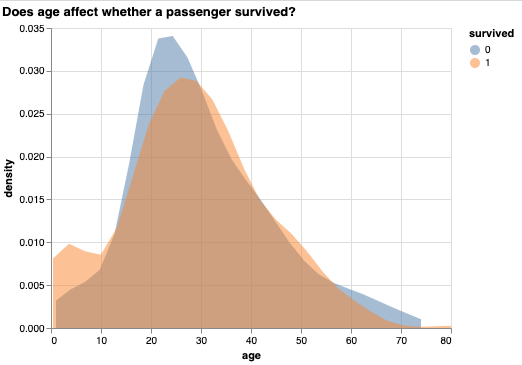
Create a chart exploring the relationship between age and survived in the titanic dataset. A strip plot, density plot, or boxplot might be useful here. Below is an example of a density plot. Feel free to replicate this chart or create your own.
The purpose of making this chart is to explore the relationships between a feature and the target. We want to see if the feature contains predictive information about the target. This is a large part of machine learning called Exploratory Data Analysis that should never be skipped! Spend time getting to know your features and how they interact with other features and the target.
Exercise 3
Build a random forest model that is able to predict whether a passenger survived. This exercise is the bulk of the skill builder and contains several steps.
Step 0: Split the data into X and y variables
The X variable will contain all your features
# Removes the target and keeps all features
X = data.drop(___, axis=1) The y variable will hold the target
# Selects the target column
y = data['___'] Step 1: Split data into train and test sets
The train_test_split function is useful for this task. Review the train_test_split function documentation
# Splitting X and y variables into train and test sets using stratified sampling
X_train, X_test, y_train, y_test = train_test_split(___, ___, test_size=0.3,
random_state=24, stratify=y)Step 2: Train the model
Explore the RandomForestClassifier documentation for the RandomForestClassifier. It’s not necessary to understand the inner workings of the Random Forest algorithm for this class - just learn the syntax of fitting the model.
# Creating random forest object
rf = RandomForestClassifier(random_state=24)
# Fit with the training data
rf.fit(___, ___) Step 3: Use test set to make predictions
# Using the features in the test set to make predictions
y_pred = rf.predict(___) Step 4: Compare test set predictions to actual values. Calculate the accuracy.
# Comparing predictions to actual values
accuracy_score(___, ___) Exercise 4
What is the most important feature in making predictions? Why do you think this is?
Create a table that shows the feature importances in descending order. The random forest classifier has a feature importances attribute. It can be accessed by rf.feature_importances_. The table should look something like this.
| feature names | importances |
|---|---|
| fare | 0.288051 |
| sex | 0.281853 |
| age | 0.266491 |
| pclass | 0.0814224 |
| siblings_spouses_aboard | 0.0475633 |
| parents_children_aboard | 0.034619 |
See the script.